
ArcGIS集成R语言解析
分享
-
2016-04-03
R语言
概述
R是一门用于统计计算和作图的语言,但它不仅仅是一门语言,更是一个数据计算与分析的环境。R语言提供了大量的第三方功能包,从基础的统计学到机器学习,从金融分析到生物信息,从各种数据库各种语言接口到高性能计算模型,当然也包含了空间数据处理。正因为这些大量的工具包,使用R语言时就像是站在巨人的肩膀上工作。
优势
· 免费开源。这是R相较于其统计学领域的其它常用工具,例如SAS、SPSS、MATLAB,的最大优势。
· 作为专门为统计和数据分析开发的语言,各种功能和函数琳琅满目,这是相较于Python,R最大的优势,也是ArcGIS集成R的意义所在。
· 简单易学,例如语言结构相对松散,但是仍保留了程序设计语言的基础逻辑与自然的语言风格。
· 安装轻便。安装程序只有150M左右,小巧玲珑,对系统负担非常小。
ArcGIS与R集成
概述
在2015年的全球用户大会上,ESRI官方公布了ArcGIS集成R的案例。在ArcMap和ArcGIS Pro中,直接通过Toolbox可以调用R分析源码,将R的分析能力直接作用在ArcGIS上面。所有的安装工具,示例源码都发布在了Github上,网址为https://r-arcgis.github.io/。

安装说明
(官方说明请参照以下链接:https://github.com/R-ArcGIS/r-bridge-install)
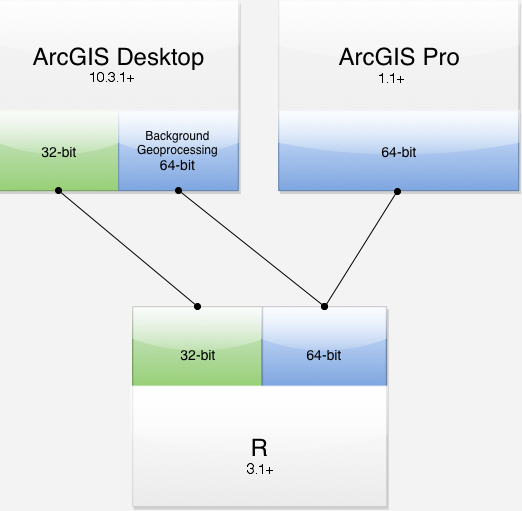
安装环境
· ArcGIS 10.3.1及其以上版本或者ArcGIS Pro 1.1及其以上版本
· R 3.1.0及其以上版本
· 对于ArcMap安装32位版本,对于ArcGIS Pro安装64位版本
· 通过安装后台处理(background processing),并且将安装运行程序配置为后台运行,64位版本即可被ArcMap使用
· 保证有网络连接的环境
安装步骤
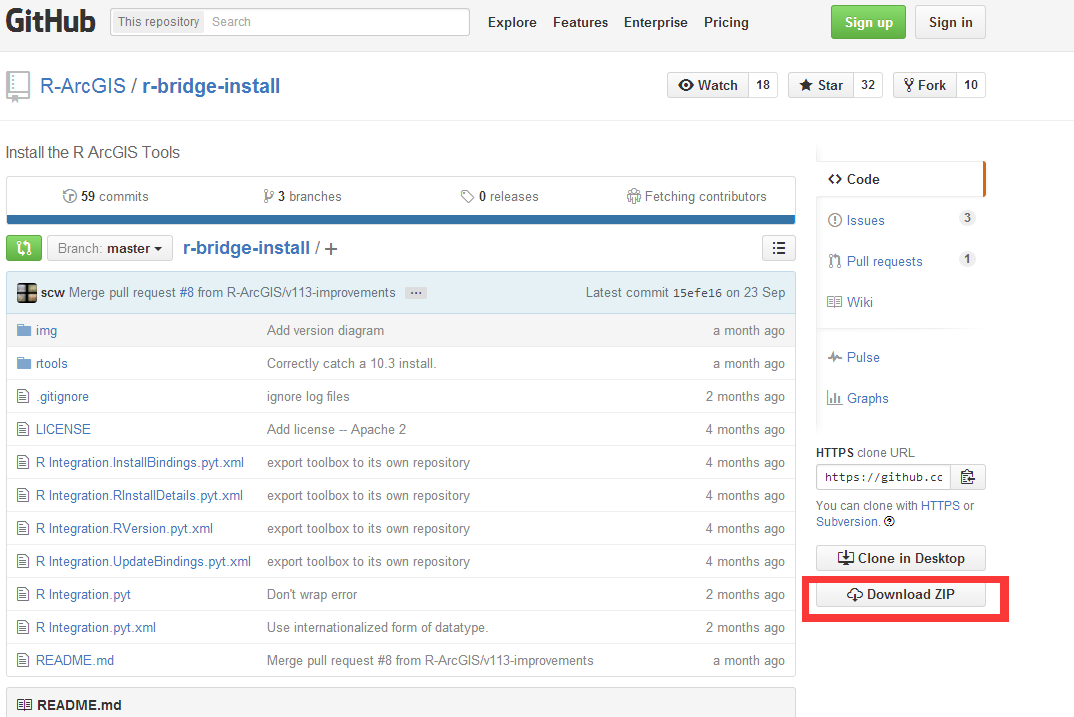
· 打开链接(https://github.com/R-ArcGIS/r-bridge-install), 下载整个压缩文件
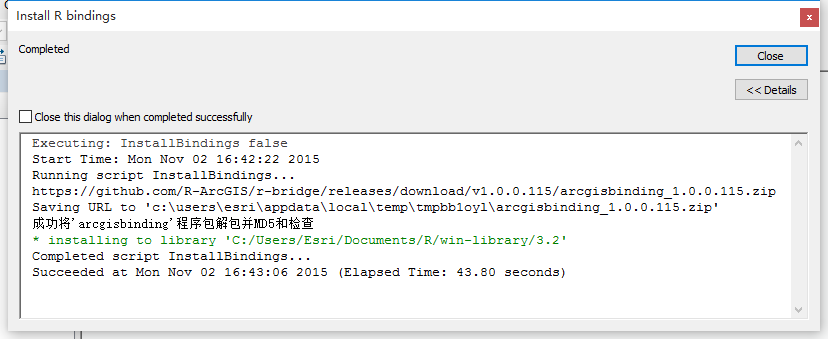
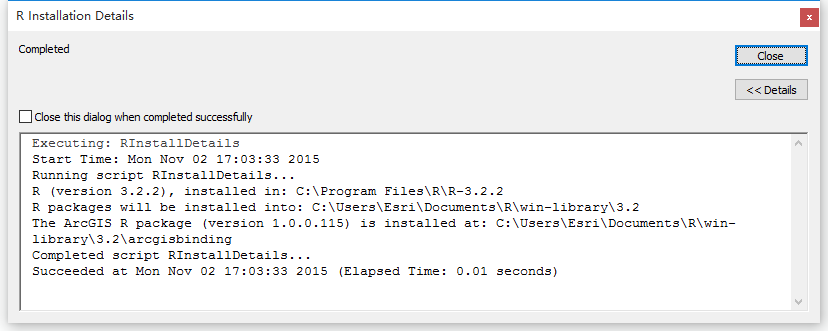
· 以管理员身份运行ArcMap,在Catalog中找到刚刚下载的GP工具,运行“Install R bindings”。安装成功后,可以运行“”来查看R版本以及“”来查看安装细节信息。

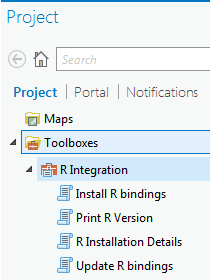
· 或者以管理员身份运行ArcGIS Pro,在Project pane中,找到刚刚下载的GP工具,步骤类似于在ArcMap中的安装。
安装中遇到的问题解决方案
安装过程中可能会遇到问题,首先检查下面几项:
· 确保ArcGIS、R版本符合要求
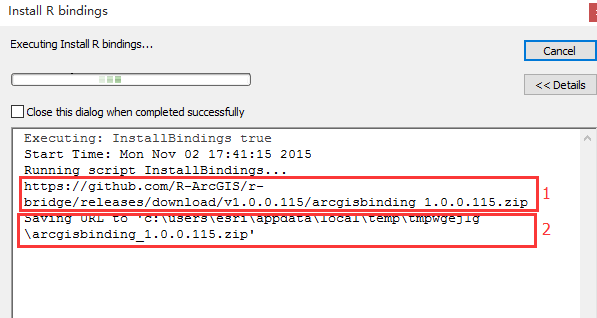
· 确保网络连接没有问题(这里如果改过host文件翻墙,可能会打不开下载arcgisbinding包的API)。(如下图:如果第一行出现问题,则检查网络连接;如果第二行出现问题,则多运行几次,可能是连接github下载文件时,网络不稳定。)
· 确保以管理员身份运行,可能会遇到权限问题
· 安装路径中没有中文
· 在Windows7环境下, KB2533623(https://support.microsoft.com/en-us/kb/2533623)需要被安装。
手动安装
如果以上方法均不能成功安装,则采用手动安装:
· 下载arcgisbinding包并解压。(https://github.com/R-ArcGIS/r- ... 0.115)
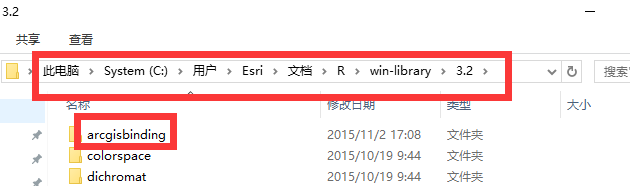
· 将“arcgisbinding”放到R目录下,一般来讲是:C:\Users<username>\Documents\R\win-library
· 在ArcGIS Desktop安装目录下(例如:C:\Program Files (x86)\ArcGIS\Desktop10.4),创建Rintegration文件夹,然后将上一步的arcgisbinding包的快捷方式拷贝到文件夹下。对于ArcGIS Pro来讲,同样在安装目录下创建Rintegration。
集成效果---arcgisbinding包介绍
ESRI提供的arcgisbinding包,使R用户可以直接读写ArcGIS支持的空间数据类型,例如shapefile、gdb等。同时,通过R-ArcGIS Bridge的安装,ArcGIS用户也可以将R源码封装成GP工具,非常方便的调用R的分析功能。
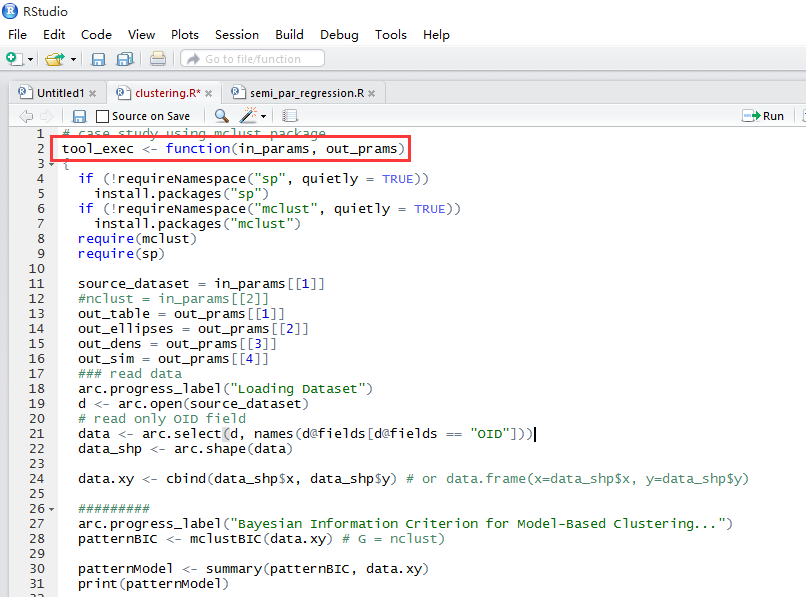
R源码的主函数如下示例,ArcGIS可以识别此主函数,其他部分我们可以根据分析需求编写自己的代码:
arcgisbinding包目前包含了17个函数(具体用法可查看arcgisbinding包里自带的pdf文件,或者直接在R里搜寻帮助文档)。下面介绍几个常用的函数:
· arc.check_product():如果不通过GP工具来运行R源码,而是直接在R里对数据进行处理分析,那么首先需要加载arcgisbinding,然后需要调用此函数建立与ArcGIS的连接。
· arc.shape(); arc.shapeinfo():读取形状信息,例如地理坐标、空间参考系等。
· arc.select():将arc.dataframe类型转换成R里普通的data frame类型,便于后续的分析。
使用说明
在ArcGIS调用R源码,与调用python类似,都是封装成GP工具来调用。具体的步骤为:
· 编写R源码实现分析:主函数为tool_exec(),接下来加载分析需要的R语言包,然后定义输入输出参数,最后是统计分析过程。
· 封装GP工具:右击toolbox 添加R源码 自定义输入输出参数,注意与R源码中的输入输出相匹配


工具示例
ESRI我们提供了两个示例,均发布在github上(https://github.com/R-ArcGIS/r-sample-tools)。大家也可以随时关注这个网站,会不定期更新应用案例。下面来具体介绍这两个官方案例(官方介绍在“\r-sample-tools-master\Documentation”文件夹下, R源码在“\r-sample-tools-master\scripts”文件夹下)。
空间聚类分析
背景介绍
空间聚类分析是将点依据其空间位置的相邻性分成几个组。最简单的方法就是最近邻聚类法,也就是根据自己设定的组数或者距离阈值来进行聚类。但是,这种聚类方法不涉及统计知识,对于空间上倾向平均分布或者类别不非常明显的案例则无法聚类。例如ArcGIS提供的aggregate points工具,只是选择距离阈值来进行聚类。所以我们需要借助R提供的更高级更复杂的统计分析方法来补充ArcGIS自带的工具的不足之处。例如,R提供的基于概率模型的聚类方法可以帮助我们回答以下几个问题:
· 最优的聚类组数是多少?
· 一个点属于这个类别的概率有多大?
· 我们应该怎样处理噪点和非正常值?
· 应该如何设定聚类模型参数使聚类更加科学和优化?
· ……
工具介绍
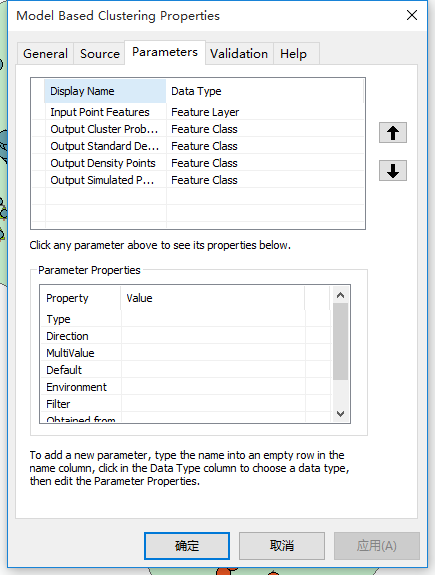
“Model Based Clustering”工具依据点的空间位置,利用R提供的mclust包,得到点的空间聚类结果。下图是工具的可视化界面。 参数定义如下:
· Input Point Features:输入待分析的点文件.
· Output Cluster Probability Points:输出的点文件包含了每个点属于的聚类后的组别和属于每个组的概率大小。
· Output Standard Deviation Ellipses:每个组的SDE
· Output Density Points:输出格网点文件,每个点包含预测的概率密度值
· Output Simulated Points:输出的依据模型预测的点文件。如果模型表现好的话,模拟的点应该与原点数据的位置分布相似。

应用案例
森林里树的位置取决于许多因素,例如其它树的位置,土壤类型,坡度,以及过去的森林管理实施方法。理想状况下,森立研究人员想要知道每一棵树的基本特征以及生长环境。但是这需要大量的资金以及人力物力,基本上是不可能的。所以,他们需要选出一些有代表性的树作为样本来了解整个森林的状况。这个案例,空间聚类分析便是此过程的一小部分。有了聚类模型,就可以预测和模拟待研究的地区相似树种,相似环境的树的分布情况。
这个案例的树木分布数据来源于航片和LiDAR。然后,将封装好的工具合ArcGIS的clip,dissolve工具相结合,用model builder为整个分析过程建立流程化的解决方案。最后我们得到了聚类分析的结果以及多种统计指标来科学的评估聚类模型。

半参数回归模型
背景介绍
在ArcGIS中提供了多种回归方法,例如地理加权回归,最小二乘法回归,探索性回归。但是却没有更多复杂高级的统计回归方法,也不能自定义选择回归标准,这就不能满足一些对回归模型精度要求很高的用户以及需要自定义回归参数和标准的用户。而在R中,用户却可以从很多R提供的回归函数中选择适合自己的,也可以自定义回归的标准。这里介绍一种高级的回归方法,半参数回归。
二值化的数据是一种很常见的数据类型,可以用0/1值来表示。例如在传染病学中,用1来表示疾病的发生,0表示没有发生。在地质学中,1表示存在某种矿物,0表示不存在某种矿物。此工具涉及到的半参数回归方法则可以用于这种二值化数据的建模。具体来讲,因变量为二值化数据,自变量包含线性变量和非线性变量两种类型。通过半参数回归方法建立回归模型,再用于之后的预测。
工具介绍
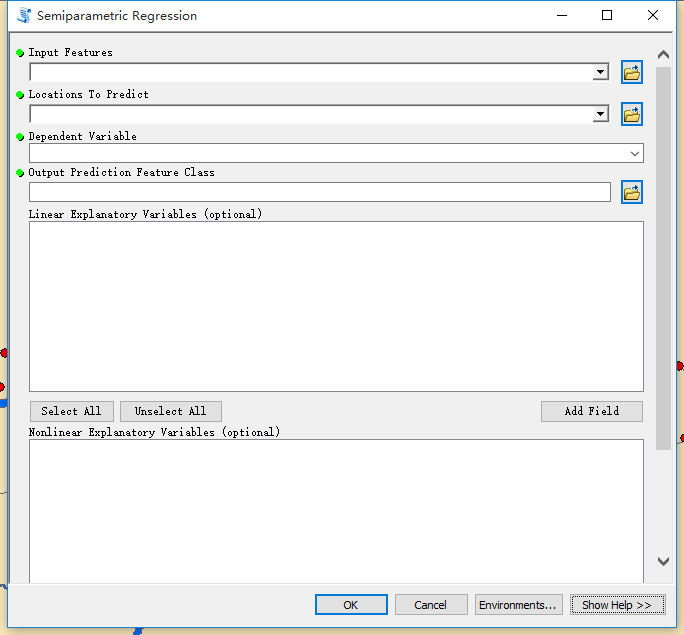
“Semiparametric Regression”利用R提供的SemiPar包,实现对二值化数据的建模和预测。工具的参数介绍如下:
· Input Feature:待回归建模的数据,包含建模所需要的属性信息。
· Location to Predict:待预测的数据。
· Dependent Variable:回归方程的因变量Y。
· Output Prediction Feature Class:输出的预测结果。包含了每个点的预测概率值以及置信区间。
· Linear Explanatory Variables:自变量X中的线性变量。
· Nonlinear Explanatory Variables:自变量X中的非线性变量。
案例
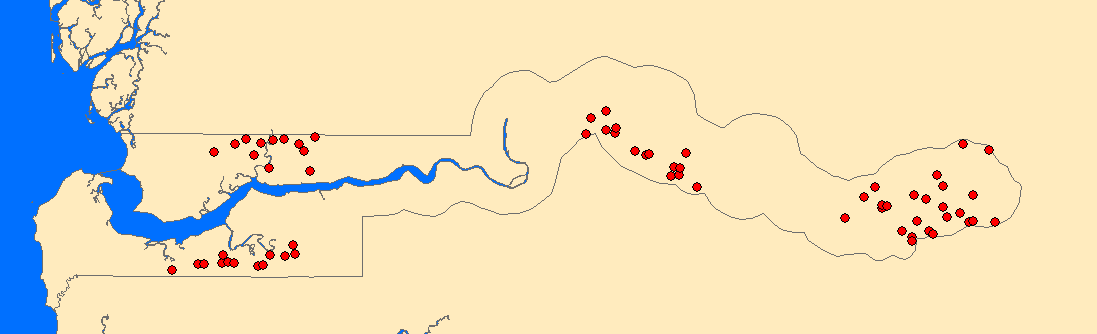
示例数据是对一个非洲国家Gambia的儿童进行的疟疾血液测试采样数据。样本共有2035个儿童,分布在65个村庄。
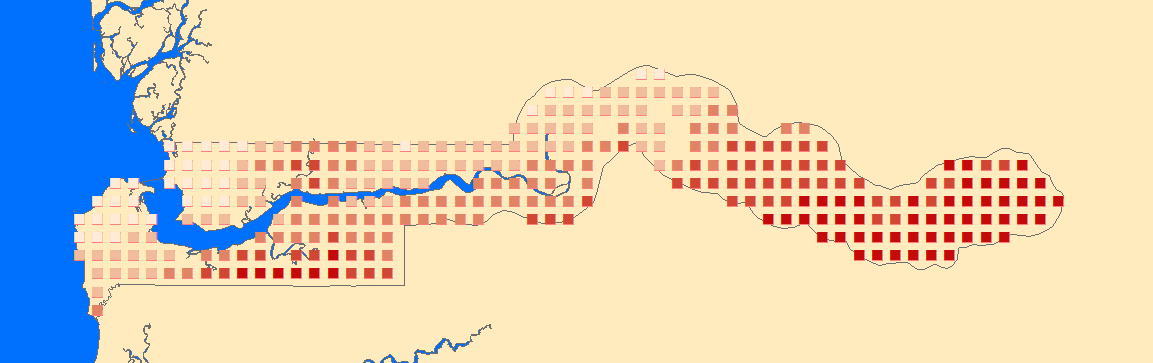
下面具体介绍变量信息:
· malaria:在被调查儿童的血液中是否检测到疟疾。有为1,无为0.
· green:绿度。这里用NDVI来量化。很多研究发现绿度是影响文字数量,疟疾传播的重要因素,而且与疟疾发生率有着非线性的关系。
· age:被调查儿童的年龄(以天为单位)。研究表明,大龄儿童更容易被感染疟疾。
· netuse:表示是否有习惯使用蚊帐。有为1,无为0. 蚊帐的使用可以一定程度上降低被蚊虫叮咬的可能。而蚊虫是疟疾的主要传播途径之一,所以使用蚊帐也可以降低疟疾发生的风险。
· healthcenter:疟疾是一种可治愈的疾病,所以对健康中心,医院的可达性和便利程度也是影响疟疾发生的重要线性指标。有为1,无为0
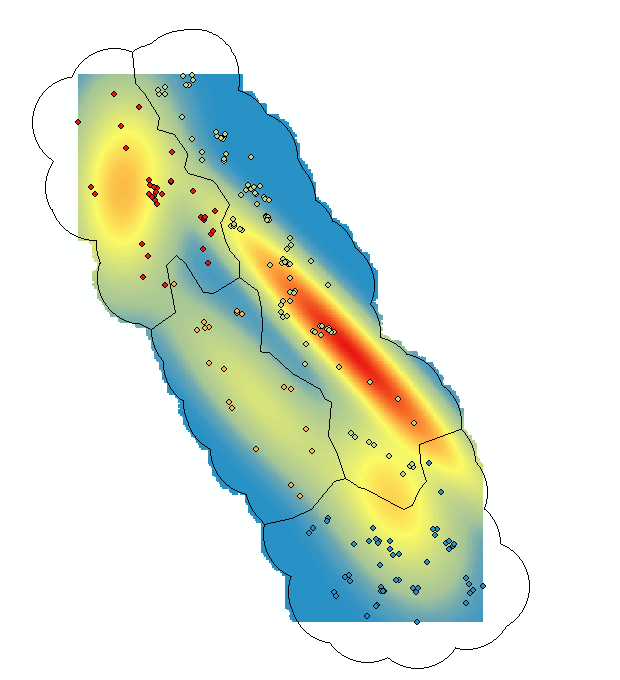
这样,就可以根据绿度,儿童的年龄,是否有使用蚊帐的习惯,以及周围是否有健康中心来预测疟疾的发病率的分布。这里,我们预测的是3岁儿童,没有使用蚊帐习惯,而且周围没有健康中心的情况下,疟疾的发生率在Gambia的分布情况。预测结果如下,红色越深则发病率越高。

制定及修订记录

概述
R是一门用于统计计算和作图的语言,但它不仅仅是一门语言,更是一个数据计算与分析的环境。R语言提供了大量的第三方功能包,从基础的统计学到机器学习,从金融分析到生物信息,从各种数据库各种语言接口到高性能计算模型,当然也包含了空间数据处理。正因为这些大量的工具包,使用R语言时就像是站在巨人的肩膀上工作。
优势
· 免费开源。这是R相较于其统计学领域的其它常用工具,例如SAS、SPSS、MATLAB,的最大优势。
· 作为专门为统计和数据分析开发的语言,各种功能和函数琳琅满目,这是相较于Python,R最大的优势,也是ArcGIS集成R的意义所在。
· 简单易学,例如语言结构相对松散,但是仍保留了程序设计语言的基础逻辑与自然的语言风格。
· 安装轻便。安装程序只有150M左右,小巧玲珑,对系统负担非常小。
ArcGIS与R集成
概述
在2015年的全球用户大会上,ESRI官方公布了ArcGIS集成R的案例。在ArcMap和ArcGIS Pro中,直接通过Toolbox可以调用R分析源码,将R的分析能力直接作用在ArcGIS上面。所有的安装工具,示例源码都发布在了Github上,网址为https://r-arcgis.github.io/。
安装说明
(官方说明请参照以下链接:https://github.com/R-ArcGIS/r-bridge-install)
安装环境
· ArcGIS 10.3.1及其以上版本或者ArcGIS Pro 1.1及其以上版本
· R 3.1.0及其以上版本
· 对于ArcMap安装32位版本,对于ArcGIS Pro安装64位版本
· 通过安装后台处理(background processing),并且将安装运行程序配置为后台运行,64位版本即可被ArcMap使用
· 保证有网络连接的环境
安装步骤
· 打开链接(https://github.com/R-ArcGIS/r-bridge-install), 下载整个压缩文件
· 以管理员身份运行ArcMap,在Catalog中找到刚刚下载的GP工具,运行“Install R bindings”。安装成功后,可以运行“”来查看R版本以及“”来查看安装细节信息。
· 或者以管理员身份运行ArcGIS Pro,在Project pane中,找到刚刚下载的GP工具,步骤类似于在ArcMap中的安装。
安装中遇到的问题解决方案
安装过程中可能会遇到问题,首先检查下面几项:
· 确保ArcGIS、R版本符合要求
· 确保网络连接没有问题(这里如果改过host文件翻墙,可能会打不开下载arcgisbinding包的API)。(如下图:如果第一行出现问题,则检查网络连接;如果第二行出现问题,则多运行几次,可能是连接github下载文件时,网络不稳定。)
· 确保以管理员身份运行,可能会遇到权限问题
· 安装路径中没有中文
· 在Windows7环境下, KB2533623(https://support.microsoft.com/en-us/kb/2533623)需要被安装。
手动安装
如果以上方法均不能成功安装,则采用手动安装:
· 下载arcgisbinding包并解压。(https://github.com/R-ArcGIS/r- ... 0.115)
· 将“arcgisbinding”放到R目录下,一般来讲是:C:\Users<username>\Documents\R\win-library
· 在ArcGIS Desktop安装目录下(例如:C:\Program Files (x86)\ArcGIS\Desktop10.4),创建Rintegration文件夹,然后将上一步的arcgisbinding包的快捷方式拷贝到文件夹下。对于ArcGIS Pro来讲,同样在安装目录下创建Rintegration。
集成效果---arcgisbinding包介绍
ESRI提供的arcgisbinding包,使R用户可以直接读写ArcGIS支持的空间数据类型,例如shapefile、gdb等。同时,通过R-ArcGIS Bridge的安装,ArcGIS用户也可以将R源码封装成GP工具,非常方便的调用R的分析功能。
R源码的主函数如下示例,ArcGIS可以识别此主函数,其他部分我们可以根据分析需求编写自己的代码:
tool_exec <- function(in_params, out_params){
input1 <- in_params[1]
input2 <- in_params[2]
ouput1 <- out_params[1]
……
return(out_params)
}
arcgisbinding包目前包含了17个函数(具体用法可查看arcgisbinding包里自带的pdf文件,或者直接在R里搜寻帮助文档)。下面介绍几个常用的函数:
· arc.check_product():如果不通过GP工具来运行R源码,而是直接在R里对数据进行处理分析,那么首先需要加载arcgisbinding,然后需要调用此函数建立与ArcGIS的连接。
library(arcgisbinding)
arc.check_product()
· arc.shape(); arc.shapeinfo():读取形状信息,例如地理坐标、空间参考系等。
· arc.select():将arc.dataframe类型转换成R里普通的data frame类型,便于后续的分析。
使用说明
在ArcGIS调用R源码,与调用python类似,都是封装成GP工具来调用。具体的步骤为:
· 编写R源码实现分析:主函数为tool_exec(),接下来加载分析需要的R语言包,然后定义输入输出参数,最后是统计分析过程。
· 封装GP工具:右击toolbox 添加R源码 自定义输入输出参数,注意与R源码中的输入输出相匹配
工具示例
ESRI我们提供了两个示例,均发布在github上(https://github.com/R-ArcGIS/r-sample-tools)。大家也可以随时关注这个网站,会不定期更新应用案例。下面来具体介绍这两个官方案例(官方介绍在“\r-sample-tools-master\Documentation”文件夹下, R源码在“\r-sample-tools-master\scripts”文件夹下)。
空间聚类分析
背景介绍
空间聚类分析是将点依据其空间位置的相邻性分成几个组。最简单的方法就是最近邻聚类法,也就是根据自己设定的组数或者距离阈值来进行聚类。但是,这种聚类方法不涉及统计知识,对于空间上倾向平均分布或者类别不非常明显的案例则无法聚类。例如ArcGIS提供的aggregate points工具,只是选择距离阈值来进行聚类。所以我们需要借助R提供的更高级更复杂的统计分析方法来补充ArcGIS自带的工具的不足之处。例如,R提供的基于概率模型的聚类方法可以帮助我们回答以下几个问题:
· 最优的聚类组数是多少?
· 一个点属于这个类别的概率有多大?
· 我们应该怎样处理噪点和非正常值?
· 应该如何设定聚类模型参数使聚类更加科学和优化?
· ……
工具介绍
“Model Based Clustering”工具依据点的空间位置,利用R提供的mclust包,得到点的空间聚类结果。下图是工具的可视化界面。 参数定义如下:
· Input Point Features:输入待分析的点文件.
· Output Cluster Probability Points:输出的点文件包含了每个点属于的聚类后的组别和属于每个组的概率大小。
· Output Standard Deviation Ellipses:每个组的SDE
· Output Density Points:输出格网点文件,每个点包含预测的概率密度值
· Output Simulated Points:输出的依据模型预测的点文件。如果模型表现好的话,模拟的点应该与原点数据的位置分布相似。
应用案例
森林里树的位置取决于许多因素,例如其它树的位置,土壤类型,坡度,以及过去的森林管理实施方法。理想状况下,森立研究人员想要知道每一棵树的基本特征以及生长环境。但是这需要大量的资金以及人力物力,基本上是不可能的。所以,他们需要选出一些有代表性的树作为样本来了解整个森林的状况。这个案例,空间聚类分析便是此过程的一小部分。有了聚类模型,就可以预测和模拟待研究的地区相似树种,相似环境的树的分布情况。
这个案例的树木分布数据来源于航片和LiDAR。然后,将封装好的工具合ArcGIS的clip,dissolve工具相结合,用model builder为整个分析过程建立流程化的解决方案。最后我们得到了聚类分析的结果以及多种统计指标来科学的评估聚类模型。
半参数回归模型
背景介绍
在ArcGIS中提供了多种回归方法,例如地理加权回归,最小二乘法回归,探索性回归。但是却没有更多复杂高级的统计回归方法,也不能自定义选择回归标准,这就不能满足一些对回归模型精度要求很高的用户以及需要自定义回归参数和标准的用户。而在R中,用户却可以从很多R提供的回归函数中选择适合自己的,也可以自定义回归的标准。这里介绍一种高级的回归方法,半参数回归。
二值化的数据是一种很常见的数据类型,可以用0/1值来表示。例如在传染病学中,用1来表示疾病的发生,0表示没有发生。在地质学中,1表示存在某种矿物,0表示不存在某种矿物。此工具涉及到的半参数回归方法则可以用于这种二值化数据的建模。具体来讲,因变量为二值化数据,自变量包含线性变量和非线性变量两种类型。通过半参数回归方法建立回归模型,再用于之后的预测。
工具介绍
“Semiparametric Regression”利用R提供的SemiPar包,实现对二值化数据的建模和预测。工具的参数介绍如下:
· Input Feature:待回归建模的数据,包含建模所需要的属性信息。
· Location to Predict:待预测的数据。
· Dependent Variable:回归方程的因变量Y。
· Output Prediction Feature Class:输出的预测结果。包含了每个点的预测概率值以及置信区间。
· Linear Explanatory Variables:自变量X中的线性变量。
· Nonlinear Explanatory Variables:自变量X中的非线性变量。
案例
示例数据是对一个非洲国家Gambia的儿童进行的疟疾血液测试采样数据。样本共有2035个儿童,分布在65个村庄。
下面具体介绍变量信息:
· malaria:在被调查儿童的血液中是否检测到疟疾。有为1,无为0.
· green:绿度。这里用NDVI来量化。很多研究发现绿度是影响文字数量,疟疾传播的重要因素,而且与疟疾发生率有着非线性的关系。
· age:被调查儿童的年龄(以天为单位)。研究表明,大龄儿童更容易被感染疟疾。
· netuse:表示是否有习惯使用蚊帐。有为1,无为0. 蚊帐的使用可以一定程度上降低被蚊虫叮咬的可能。而蚊虫是疟疾的主要传播途径之一,所以使用蚊帐也可以降低疟疾发生的风险。
· healthcenter:疟疾是一种可治愈的疾病,所以对健康中心,医院的可达性和便利程度也是影响疟疾发生的重要线性指标。有为1,无为0
这样,就可以根据绿度,儿童的年龄,是否有使用蚊帐的习惯,以及周围是否有健康中心来预测疟疾的发病率的分布。这里,我们预测的是3岁儿童,没有使用蚊帐习惯,而且周围没有健康中心的情况下,疟疾的发生率在Gambia的分布情况。预测结果如下,红色越深则发病率越高。
制定及修订记录

