
白话空间统计二十七:统计学七支柱之空间统计版本(三)信息的数量(2)
分享
-
2019-01-23
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/allenlu2 ... 51224
前文继续,书接上一回。
从大数据的角度来说,数据获取得越多,那么越接近真相——甚至在《大数据时代》一书中,还出现了“全量数据分析”这一概念。理论上是没错,就像询问我们出行的时候,需要多快速度的交通工具一样?回答肯定是“越快越好”,最好是破开空间,瞬间移动……那么这就是最快的么?错了,还有更快的,就是破开时间线,追上了时间……在出发之前,就已经到达了目的地……好吧,这个逻辑过于烧脑,不做解释不做讨论了。
虽然说,理想总还是有的,万一实现了呢……但是关于理论存在这种事情……比如理论上,虾神也是可以成为紧密团结核心的……因为虾神我符合一切条件啊,土生土长中国公民神马的,但是,成功的几率,无限等于0……
所以,还是要现实一点,全数据分析前景很美好,实际上各种困难重重。也就是在数据分析领域,抽样依然是核心,所以在大数据界的另外一种声音就是:大数据的目的(之一)就是生产小数据。

如何从数据中抽样获取成为最佳的信息,在第一节的时候我们讲过聚合的概念,聚合最初始化的应用就是平均数……但是在统计学界有个公案:就是如果你有多份不相等的数据,那么随机抽取其中一份的准确度,都要比计算平均数要来的准确,比如有这样一个案例:
一位舰长计划夺取敌人的一座要塞,他派了两名间谍潜入要塞,并要求其返回报告要塞中加农炮的口径,如此就可以准备尺寸合适的加农炮弹,以确保夺取要塞后可以加强防守。一名间谍报告口径是8英寸,另一名报告是9英寸,那么舰长应该配置8.5英寸的加农炮弹吗?当然不会,无论哪种情况,这个炮弹都不能用。哪怕扔硬币决定取两种尺寸中的某一种,都好过注定失败的平均值。
当然,国产神剧里面,这个完全不是问题,口径不对,我们用锉刀挫就行……

虽然我不知道17毫米的炮是啥炮……一般20毫米以下的通常叫做枪,18毫米,也就是普通人大拇指这么粗吧……二战时候日军的迫击炮的口径都是50毫米。
下面进入正题……
非空间数据的抽样,只要保证了抽样的随机性就可以了,但是空间数据的抽样就不能是简简单单的把获取子集就可以了。因为在空间数据的分析中,最重要的概念是所谓的空间关系矩阵。而数据一旦发生抽样变化,那么相应的空间关系肯定就会发生变化,不同的空间关系下,就算同样的数据,也会得出完全不同的结果(空间异质性、空间异质性、空间异质性……重要的事情说三遍)。
那么怎么样在保证空间关系不变的情况下,进行空间数据抽样呢?(当然,也有的同学会问,你前面那篇文章,直接抽样计算空间自相关,不是也正常的么?答案是我抽样之后,重新计算了空间关系矩阵,实际上他们的空间关系也是发生了一定的变异的。)
最简单的方法,就是进行网格抽样和聚合。
实际上这个例子我一直在说,这里又翻出来说一遍:
比如一个城市的车辆的LBS数据,数据的体量是极其庞大的,如果用这样的数据来进行空间分析计算,难度之大可想而知:
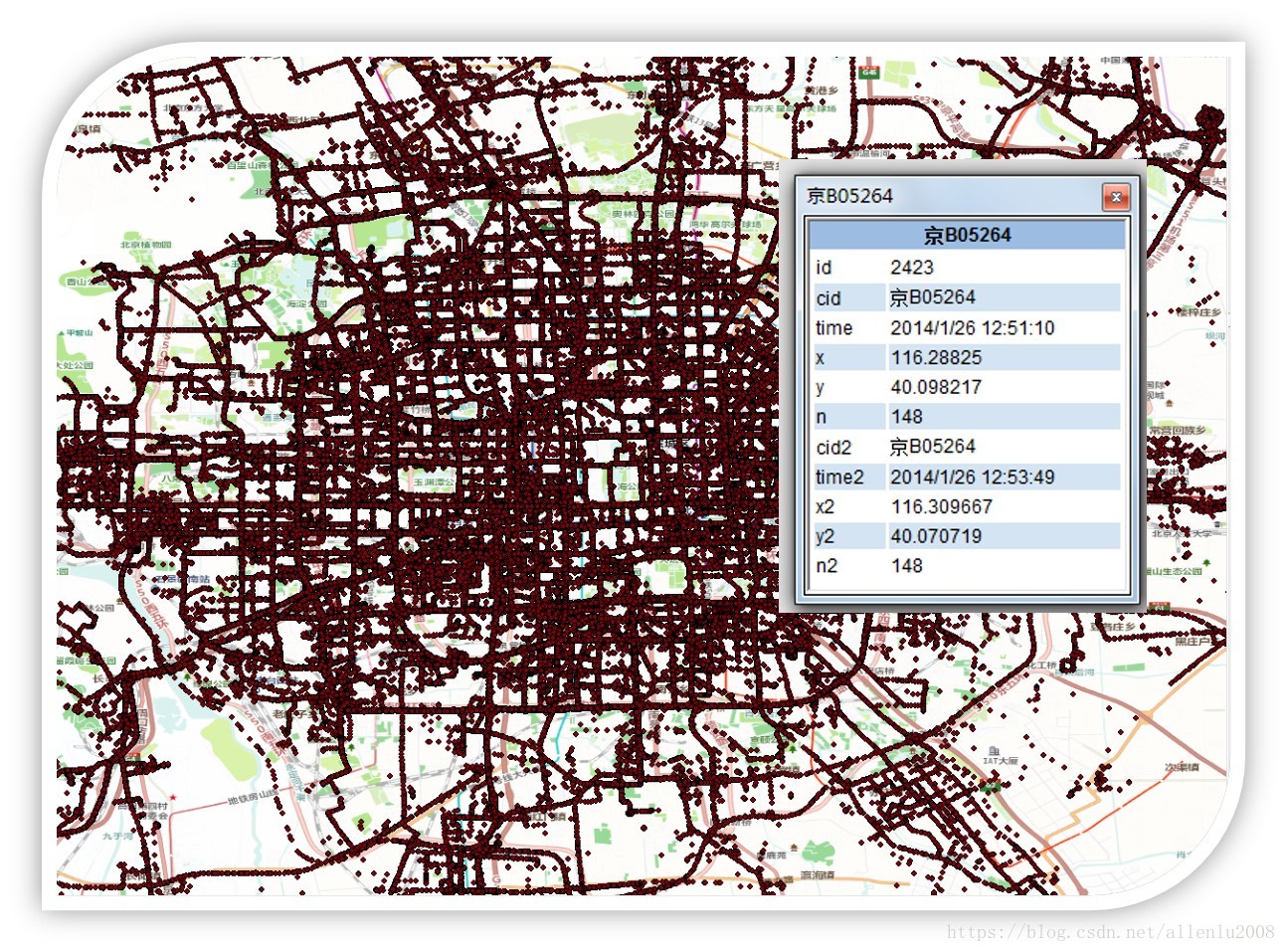
将北京市一个时间切片的LBS铺到地图上,已经超过了数十万这个级数。
因为车辆轨迹这种数据具有时间连续性,所以如果你采用简单的随机抽样,抽出来的数据肯定就直接破坏掉了这种特征,况且:

抽样率你准备设定为多少?百分之九十?百分之五十?哪怕你抽样到百分之一……以亿为单位的数据,抽百分之一出来,依然还有一百万……下面的情况依然会出现:

遇上这种情况,有同学会说,硬件能解决的问题,都不是问题,我们不是还有大数据么……也就是:

先不论在分布式计算环境下,如何解决空间相关性的各种大问题,单单是各种经典空间统计学的算法改造成为分布式条件下的运算,就能要了老命了……当然,有志于在计算机算法、大数据算法、和空间统计学算法三个方面有跨界研究兴趣的同学,可以和我联系……
下面继续我们的统计抽样:
那么现在我手上就是这样一份轨迹数据,我要用来研究北京市城市路况信息的空间分布模式,那么怎么来做呢?一天24小时,按照10秒一个采样点的频率,北京8万辆出租车,一天的数据量就是六亿九千万个点……
如果生算的话,我的脑海里面又出现了这样一个进度条……
那么有没有什么方法,能够快速获得整个北京市全天24小时交通流量空间分布模式指数呢?答案就是数据的抽样聚合。
步骤实现如下:
首先,将研究区域划分成若干个大小相等的格网(四边形或者六边形都可以),格网划分的大小,可以安装样方分析的算法来实现,也可以按照自定义的粒度来做,我这里用的是1公里的蜂窝格网将北京主城区划划分成了11300多个六边形,划分情况如下:

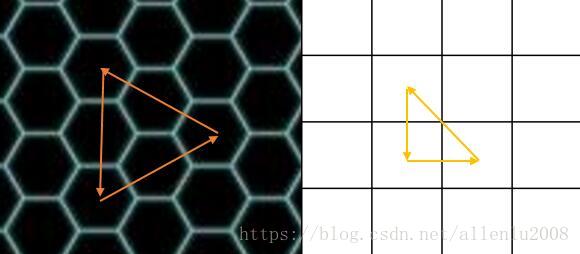
这里为什么要用六边形呢(因为这是虾神以前做的,他在偷懒),因为六边形是最接近园形的无缝多边形:
接下去,依照这个格网,将所有的点数据进行聚合,并且按照时间进行切片,比如这里按照1小时为时间窗,具体的方法就是将落在同一个格网里面的点的标志性统计值进行计算输出,比如车辆数、轨迹点数、最高时速、最低时速、平均速度、非零车辆数目(非零表示车辆在运行状态,而非停车趴活状态)等等。
结果如下:
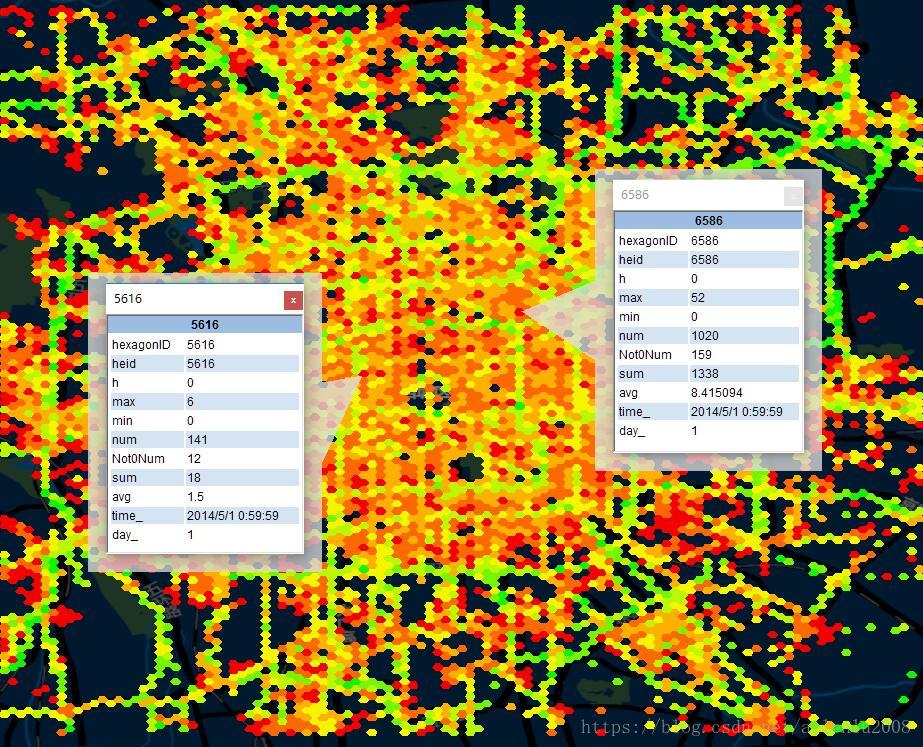
然后,以亿为单位的数据,就变成了24个切片,每个切片只有1万多条记录。这一万多条记录,代表的就是这个切片时间段内,城市的交通情况(用每个采样网格的平均时速为特征值),然后对他们进行空间自相关计算,计算结果如下:
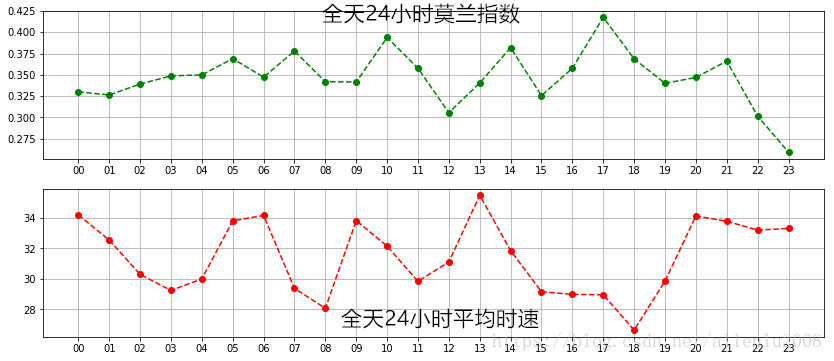
北京市的出租车(以平均时速为特征)空间分布情况可以表明,全天24小时,均呈现空间正相关状态,聚集的趋势明显,其中最高值是下午的17点,最低值是晚上23点。
然后我们提取17点和23点这两个极值进行局部莫兰指数(Anselin local moran's I)的计算,看看这两个时间段的交通特征:

从图上可以看出,17时,在市区内部,有大片区域呈现淡蓝色(Low-Low Cluster低值聚类),而城外(五环外)的环线上出现了线性的高值聚类,表示在这个时间段内,主要交通压力都集中在市区内。
而23时的时候,低值聚类的区域转移到了环城区域,高值聚集的区域变成了几条连接城内外的交通枢纽道路。
关于局部莫兰指数的基础内容,大家可以回顾以前的文章,以后在后续的文章中,会不断出现。
(待续未完)
文章来源:https://blog.csdn.net/allenlu2008/article/details/82151224
前文继续,书接上一回。
从大数据的角度来说,数据获取得越多,那么越接近真相——甚至在《大数据时代》一书中,还出现了“全量数据分析”这一概念。理论上是没错,就像询问我们出行的时候,需要多快速度的交通工具一样?回答肯定是“越快越好”,最好是破开空间,瞬间移动……那么这就是最快的么?错了,还有更快的,就是破开时间线,追上了时间……在出发之前,就已经到达了目的地……好吧,这个逻辑过于烧脑,不做解释不做讨论了。
虽然说,理想总还是有的,万一实现了呢……但是关于理论存在这种事情……比如理论上,虾神也是可以成为紧密团结核心的……因为虾神我符合一切条件啊,土生土长中国公民神马的,但是,成功的几率,无限等于0……
所以,还是要现实一点,全数据分析前景很美好,实际上各种困难重重。也就是在数据分析领域,抽样依然是核心,所以在大数据界的另外一种声音就是:大数据的目的(之一)就是生产小数据。
如何从数据中抽样获取成为最佳的信息,在第一节的时候我们讲过聚合的概念,聚合最初始化的应用就是平均数……但是在统计学界有个公案:就是如果你有多份不相等的数据,那么随机抽取其中一份的准确度,都要比计算平均数要来的准确,比如有这样一个案例:
一位舰长计划夺取敌人的一座要塞,他派了两名间谍潜入要塞,并要求其返回报告要塞中加农炮的口径,如此就可以准备尺寸合适的加农炮弹,以确保夺取要塞后可以加强防守。一名间谍报告口径是8英寸,另一名报告是9英寸,那么舰长应该配置8.5英寸的加农炮弹吗?当然不会,无论哪种情况,这个炮弹都不能用。哪怕扔硬币决定取两种尺寸中的某一种,都好过注定失败的平均值。
当然,国产神剧里面,这个完全不是问题,口径不对,我们用锉刀挫就行……
虽然我不知道17毫米的炮是啥炮……一般20毫米以下的通常叫做枪,18毫米,也就是普通人大拇指这么粗吧……二战时候日军的迫击炮的口径都是50毫米。
下面进入正题……
非空间数据的抽样,只要保证了抽样的随机性就可以了,但是空间数据的抽样就不能是简简单单的把获取子集就可以了。因为在空间数据的分析中,最重要的概念是所谓的空间关系矩阵。而数据一旦发生抽样变化,那么相应的空间关系肯定就会发生变化,不同的空间关系下,就算同样的数据,也会得出完全不同的结果(空间异质性、空间异质性、空间异质性……重要的事情说三遍)。
那么怎么样在保证空间关系不变的情况下,进行空间数据抽样呢?(当然,也有的同学会问,你前面那篇文章,直接抽样计算空间自相关,不是也正常的么?答案是我抽样之后,重新计算了空间关系矩阵,实际上他们的空间关系也是发生了一定的变异的。)
最简单的方法,就是进行网格抽样和聚合。
实际上这个例子我一直在说,这里又翻出来说一遍:
比如一个城市的车辆的LBS数据,数据的体量是极其庞大的,如果用这样的数据来进行空间分析计算,难度之大可想而知:
将北京市一个时间切片的LBS铺到地图上,已经超过了数十万这个级数。
因为车辆轨迹这种数据具有时间连续性,所以如果你采用简单的随机抽样,抽出来的数据肯定就直接破坏掉了这种特征,况且:
抽样率你准备设定为多少?百分之九十?百分之五十?哪怕你抽样到百分之一……以亿为单位的数据,抽百分之一出来,依然还有一百万……下面的情况依然会出现:
遇上这种情况,有同学会说,硬件能解决的问题,都不是问题,我们不是还有大数据么……也就是:
先不论在分布式计算环境下,如何解决空间相关性的各种大问题,单单是各种经典空间统计学的算法改造成为分布式条件下的运算,就能要了老命了……当然,有志于在计算机算法、大数据算法、和空间统计学算法三个方面有跨界研究兴趣的同学,可以和我联系……
下面继续我们的统计抽样:
那么现在我手上就是这样一份轨迹数据,我要用来研究北京市城市路况信息的空间分布模式,那么怎么来做呢?一天24小时,按照10秒一个采样点的频率,北京8万辆出租车,一天的数据量就是六亿九千万个点……
如果生算的话,我的脑海里面又出现了这样一个进度条……
那么有没有什么方法,能够快速获得整个北京市全天24小时交通流量空间分布模式指数呢?答案就是数据的抽样聚合。
步骤实现如下:
首先,将研究区域划分成若干个大小相等的格网(四边形或者六边形都可以),格网划分的大小,可以安装样方分析的算法来实现,也可以按照自定义的粒度来做,我这里用的是1公里的蜂窝格网将北京主城区划划分成了11300多个六边形,划分情况如下:
这里为什么要用六边形呢(因为这是虾神以前做的,他在偷懒),因为六边形是最接近园形的无缝多边形:
接下去,依照这个格网,将所有的点数据进行聚合,并且按照时间进行切片,比如这里按照1小时为时间窗,具体的方法就是将落在同一个格网里面的点的标志性统计值进行计算输出,比如车辆数、轨迹点数、最高时速、最低时速、平均速度、非零车辆数目(非零表示车辆在运行状态,而非停车趴活状态)等等。
结果如下:
然后,以亿为单位的数据,就变成了24个切片,每个切片只有1万多条记录。这一万多条记录,代表的就是这个切片时间段内,城市的交通情况(用每个采样网格的平均时速为特征值),然后对他们进行空间自相关计算,计算结果如下:
北京市的出租车(以平均时速为特征)空间分布情况可以表明,全天24小时,均呈现空间正相关状态,聚集的趋势明显,其中最高值是下午的17点,最低值是晚上23点。
然后我们提取17点和23点这两个极值进行局部莫兰指数(Anselin local moran's I)的计算,看看这两个时间段的交通特征:
从图上可以看出,17时,在市区内部,有大片区域呈现淡蓝色(Low-Low Cluster低值聚类),而城外(五环外)的环线上出现了线性的高值聚类,表示在这个时间段内,主要交通压力都集中在市区内。
而23时的时候,低值聚类的区域转移到了环城区域,高值聚集的区域变成了几条连接城内外的交通枢纽道路。
关于局部莫兰指数的基础内容,大家可以回顾以前的文章,以后在后续的文章中,会不断出现。
(待续未完)
文章来源:https://blog.csdn.net/allenlu2008/article/details/82151224
