
矢量大数据(Geoanalytics Server)之 ArcGIS 矢量大数据清单介绍帖
分享
-
2018-08-20
这篇文章的目的:
理解如何将您手中的大数据接入到esri大数据处理平台。
(理解为主,具体执行参考下一篇文章--《注册大数据文件共享步骤贴》)
在大数据的环境下,有多份数据是极其正常的,其中包含历史数据和未来会产生的数据
。
如果需要在esri提供的大数据平台中处理这些“大数据”,首先需要执行注册大数据文件共享,该步骤是将平台与现有数据搭建“桥梁”;桥梁搭建的结果是在平台中生成了一份数据的清单(manifest)。
通过理解“桥梁”的两端来理解大数据和esri大数据平台的关系。
理解“桥梁”的两端
“桥梁”的一端 ----- 存储数据文件结构
首先,我们在存储数据的时候,可以遵循以下逻辑上存储的数据结构。
注:局限性---下面理解以共享文件夹和HDFS存储为例; 如果数据存储在hive或者云,请参考官方帮助文档,理解的总体思路不变。
以下示例中,我们可以看出, 在FileShareFolder文件夹下面有三个子文件夹—Earthquakes, Hurricanes和GlobalOceans;三个子文件夹中还有相关的主题数据。
三个子文件夹中 相关数据的存储可以看出以下逻辑:可以根据时间/地理位置来存放数据。
|---FileShareFolder < --被注册为大数据文件共享的首层文件夹
|---Earthquakes < --数据集“Earthquakes”,其中包含了四个 csv文件,且文件的schema相同
“桥梁”的另一端 ----根据用户数据存储生成的数据清单
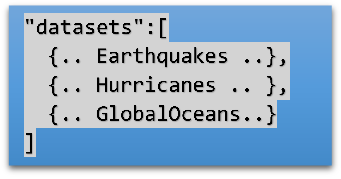
根据图一中的数据存储,大数据平台可以生成的数据清单结构如下:
为什么会是这个结果,可以继续来理解大数据文件清单(manifest)。
大数据清单相当于根据用户的数据结构,按照清单的结构,生成了一份数据的“剪影”。
数据清单本质是若干数据集信息的关键抽取,其记录的组织结构如下;每一个dataset对应用户数据的一个子文件夹,即被注册的文件夹下有多少个数据子文件夹,就有多少个dataset:
"datasets":[
{.. dataset1 ..},
{.. dataset2 ..},
{.. dataset3 ..},
{.. dataset4 ..},
{.. dataset5 ..},
]
图三
针对于每一个数据集,都会根据数据产生以下五个对象,其中name,format,schema是一定会产生的:

当一个数据集的清单内容生成了name,format,schema,geometry,则该数据集被识别为几何数据集;
当一个数据集的清单内容生成了name,format,schema,geometry,time,则该数据集被识别为几何数据集,且带有时间属性。
大数据清单tips:
1.成功注册数据清单隐含的意义:GA可以读到数据。但是成功注册不能保证百分百完成工具运行,造成失败的可能原因:
• 数据集下的数据的schema不同
• 某个工具的某个参数设置后出错
• 运算节点资源分配不对或者不足
• 运算环境搭建失败问题
2.从Portal的角度出发,大数据文件共享作为一个项目(item)出现,只有这个项目成功生成,portal使用者才能在地图查看器中执行工具的时候浏览数据。
3.特别注意:
一个数据集(dataset)里面的数据的schema必须一致,即一个子文件夹下的数据schema必须一致。
为了知道如果意外违背了上述原则后,GA会出现的错误,特意做了测试,总结如下:
根据目前测试情况,manifest是首次注册大数据文件共享的时候,随机根据一份数据生成;后续更新数据集,如果被选中的数据的schema没有变动,则manifest里面的schema内容不会更新(采取如下图更新manifest方法)。
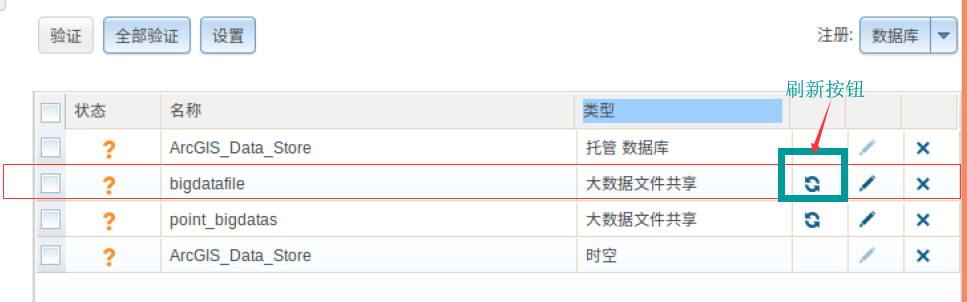
图五
所以,如果生成manifest的时候选择的数据正好是schema与其他数据不一致的情况,GA无法处理整个数据集,在执行GA工具分析的时候,会报错如下图:

图六
同时spark中会明确指出与记录的schema不同的数据,错误结果如下:

测试版本:
ArcGIS Enterprise 10.6.1 ArcGIS Geoanalytics Server 10.6.1
参考帮助:
http://enterprise.arcgis.com/en/portal/latest/use/what-is-a-big-data-file-share.htm
原始文章来源: http://www.gougexueli.com/2018/08/20/arcgis-%E7%9F%A2%E9%87%8F%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%B8%85%E5%8D%95%E4%BB%8B%E7%BB%8D%E5%B8%96/
文章来源:https://github.com/serverteamCN/TechnicalArticles/blob/master/BigData/ArcGIS%20%E7%9F%A2%E9%87%8F%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%B8%85%E5%8D%95%E4%BB%8B%E7%BB%8D%E5%B8%96.md
理解如何将您手中的大数据接入到esri大数据处理平台。
(理解为主,具体执行参考下一篇文章--《注册大数据文件共享步骤贴》)
在大数据的环境下,有多份数据是极其正常的,其中包含历史数据和未来会产生的数据
。
如果需要在esri提供的大数据平台中处理这些“大数据”,首先需要执行注册大数据文件共享,该步骤是将平台与现有数据搭建“桥梁”;桥梁搭建的结果是在平台中生成了一份数据的清单(manifest)。
通过理解“桥梁”的两端来理解大数据和esri大数据平台的关系。
理解“桥梁”的两端
“桥梁”的一端 ----- 存储数据文件结构
首先,我们在存储数据的时候,可以遵循以下逻辑上存储的数据结构。
注:局限性---下面理解以共享文件夹和HDFS存储为例; 如果数据存储在hive或者云,请参考官方帮助文档,理解的总体思路不变。
以下示例中,我们可以看出, 在FileShareFolder文件夹下面有三个子文件夹—Earthquakes, Hurricanes和GlobalOceans;三个子文件夹中还有相关的主题数据。
三个子文件夹中 相关数据的存储可以看出以下逻辑:可以根据时间/地理位置来存放数据。
|---FileShareFolder < --被注册为大数据文件共享的首层文件夹
|---Earthquakes < --数据集“Earthquakes”,其中包含了四个 csv文件,且文件的schema相同
|---1960
|---01_1960.csv
|---02_1960.csv
|---1961
|---01_1961.csv
|---02_1961.csv
|---atlantic_hur.shp
|---pacific_hur.shp
|---otherhurricanes.shp|---GlobalOceans < -- 数据集 "GlobalOceans", 包含一个shp文件
|---oceans.shp
图一
“桥梁”的另一端 ----根据用户数据存储生成的数据清单
根据图一中的数据存储,大数据平台可以生成的数据清单结构如下:
图二
为什么会是这个结果,可以继续来理解大数据文件清单(manifest)。
大数据清单相当于根据用户的数据结构,按照清单的结构,生成了一份数据的“剪影”。
数据清单本质是若干数据集信息的关键抽取,其记录的组织结构如下;每一个dataset对应用户数据的一个子文件夹,即被注册的文件夹下有多少个数据子文件夹,就有多少个dataset:
"datasets":[
{.. dataset1 ..},
{.. dataset2 ..},
{.. dataset3 ..},
{.. dataset4 ..},
{.. dataset5 ..},
]
图三
针对于每一个数据集,都会根据数据产生以下五个对象,其中name,format,schema是一定会产生的:
图四
当一个数据集的清单内容生成了name,format,schema,geometry,则该数据集被识别为几何数据集;
当一个数据集的清单内容生成了name,format,schema,geometry,time,则该数据集被识别为几何数据集,且带有时间属性。
大数据清单tips:
1.成功注册数据清单隐含的意义:GA可以读到数据。但是成功注册不能保证百分百完成工具运行,造成失败的可能原因:
• 数据集下的数据的schema不同
• 某个工具的某个参数设置后出错
• 运算节点资源分配不对或者不足
• 运算环境搭建失败问题
2.从Portal的角度出发,大数据文件共享作为一个项目(item)出现,只有这个项目成功生成,portal使用者才能在地图查看器中执行工具的时候浏览数据。
3.特别注意:
一个数据集(dataset)里面的数据的schema必须一致,即一个子文件夹下的数据schema必须一致。
为了知道如果意外违背了上述原则后,GA会出现的错误,特意做了测试,总结如下:
根据目前测试情况,manifest是首次注册大数据文件共享的时候,随机根据一份数据生成;后续更新数据集,如果被选中的数据的schema没有变动,则manifest里面的schema内容不会更新(采取如下图更新manifest方法)。
图五
所以,如果生成manifest的时候选择的数据正好是schema与其他数据不一致的情况,GA无法处理整个数据集,在执行GA工具分析的时候,会报错如下图:
图六
同时spark中会明确指出与记录的schema不同的数据,错误结果如下:
图七
测试版本:
ArcGIS Enterprise 10.6.1 ArcGIS Geoanalytics Server 10.6.1
参考帮助:
http://enterprise.arcgis.com/en/portal/latest/use/what-is-a-big-data-file-share.htm
原始文章来源: http://www.gougexueli.com/2018/08/20/arcgis-%E7%9F%A2%E9%87%8F%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%B8%85%E5%8D%95%E4%BB%8B%E7%BB%8D%E5%B8%96/
文章来源:https://github.com/serverteamCN/TechnicalArticles/blob/master/BigData/ArcGIS%20%E7%9F%A2%E9%87%8F%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%B8%85%E5%8D%95%E4%BB%8B%E7%BB%8D%E5%B8%96.md

