
ArcGIS地理大数据模式识别之热点分析
分享
-
2018-06-11
这个世界是概率的?还是因果的?从直觉上我们可能脱口而出是因果的,因为我们都知道种瓜得瓜,种豆得豆,今天的努力决定了明天的成就,这些似乎都证明着世界的因果性。但是随着概率统计学和量子力学在今天发挥的巨大作用,科学家在用事实告诉我们也许世界的本色是概率的。到亚原子粒子级别,测量会决定量子的状态,数万次掷骰子,得到的结果会呈现出概率分布规律,他们似乎遵从了某种神秘的自然法则一样让人心生敬畏,概率统计的科学方法论为我们从数据中洞察规律,预测未来提供了可能。
ArcGIS 作为对GIS研究成果的最佳实践,为我们提供了大量强大、易用的工具,这篇文章就跟大家分享一个构建在统计推断之上的大数据空间模式分析工具——查找热点(Find Hot Spots)。
功能定义
何谓热点?是不是点越密越热?当我们把代表事件的点绘制到地图上,以人类上亿像素的高分辨率双眼和超强大脑,似乎不用工具我们也能看出哪儿密哪儿疏,那为啥还需要分析热点?不会只是为了告诉我们“你看的对”吧?
当然不是,事实上正是因为我们几乎在任何时候都在不自觉的发掘事物的规律和模式,很多时候我们把随机事件解读成了强关联关系,从而导致了决策的失误。对于随机事件呈现的自然规律,不是我们研究的重点,但是如果事件在空间上表现出了强空间关联性,就说明某些空间过程因子正在影响这些事件的发生(此处必有猫腻),这就很重要了,通过获得这些信息:一是我们可以将有限的资源投放到更需要的地方,做到更合理的资源分配,二是通过锁定问题区域,可以进一步发掘背后的关联因子,指导管理。
查找热点工具就是帮助我们实现上述数据挖掘的工具,这里真正关心的是统计意义上的热点和冷点。简单下个定义:“查找热点”是用来发掘数据特征在空间模式上是否存在任何统计显著性聚类的工具。
使用工具
热点工具背后的原理稍复杂,但是使用上非常简单,特别是对大数据分析工具中的查找热点工具,相比桌面中对等的工具要更简单清爽些:
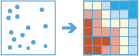
基本工作流,依然遵从三段式:输入-执行分析-输出
输入参数
1, 输入点数据:大数据工具中的查找热点工具目前只支持对点图层的分析,这个点数据应该是代表了某一要素特征的,比如犯罪事件,交通事故等等;
2,设置聚合条柱:聚合条柱用来汇聚输入的点数据到每一个格网,相当于以条柱格网为目标图层,join输入的点数据,实际参与分析计算的是聚合条柱,从这个角度来看,这个工具实质是在针对条柱面图层进行热点分析;
3,设置热点分析的邻域大小:邻域就是分析区,邻域设置的大小要大于聚合条柱,也就是必须要确保一定的统计样本量,过小分析会失败;
4,设置时间步长:这步是可选的,一旦设置了时间步长,分析就会基于每个时间步长内的要素进行分析,如果时间步长过小,那参与的要素数可能低于分析工具要求的最小要素数导致分析失败;
5,设置输出图层名。
6,设置空间参考:既然要用到聚合条柱,聚合条柱是基于投影坐标由程序动态计算的,所以在工具环境变量的设置中,需要设置投影坐标系统,比如我们常用的web_mercator投影3857。
7,最后,还可以选择是否按照当前地图范围分析。
分析过程
从输入的参数和对热点分析工具计算公式了解的基础上,能大致分析出工具背后执行的分析过程;
1,先将点数据按照条柱格网重新聚合为新的待分析图层,每个条柱的count值代表落入的点数,这代表了事件数;
2,以每个条柱格网为中心,按照邻域半径重新划分本地计算分区;
3,按照每个计算分区计算ZScore, PValue和Gi_bin,并将结果以属性的形式附加到聚合条柱图层;
输出结果
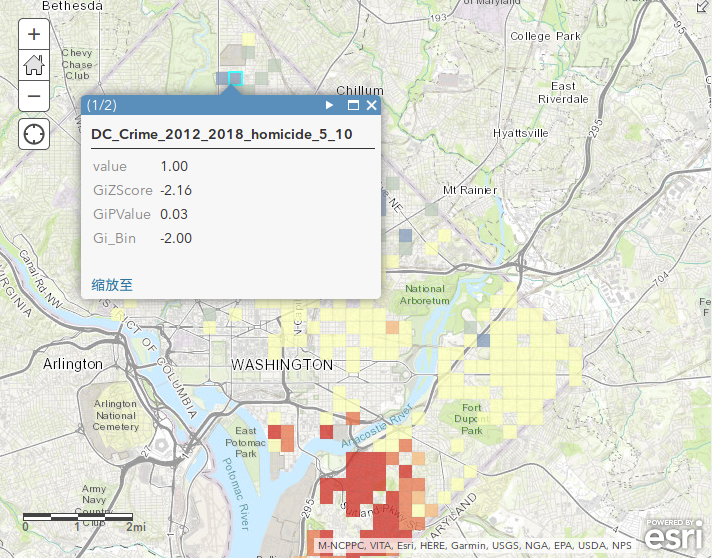
查找热点工具的结果以属性字段的形式添加到聚合条柱图层上,添加GiZScore, GiPValue, Gi_Bin三个字段,结果图层渲染默认是以Gi_Bin字段进行唯一值渲染,高值采用偏暖色的红色,低值采用偏冷色的蓝色。
这三个字段都和统计推断的假设检验相关,这三个字段的含义需要在了解计算原理之后才能解释清楚,在此先跳过。但是大家需要清楚热点分析工具的分析目标:是要找出要素特征在空间分布上明显存在统计显著性聚类的区域,也就是ZScore的高值区和低值区。
什么是ZScore, PValue和Gi-bin?接下来我们就来看看工具背后运行的原理。
原理分析
热点分析工具的统计模型是基于 Getis-Ord Gi*统计(读音是G-i-star),先来解释下这个模型名称的由来:
热点分析是构建在统计推断中常用的零假设检验的思想之上的。由于我们的眼睛和大脑无时无刻不在分析数据背后的模式,即使是随机分布的事件在空间上也可能表现出某种程度的集聚,热点分析工具的目标就是识别出具有统计显著性聚类的区域,因为这说明这些事件正在受某些空间过程因子的影响,存在空间上的关联性。接下来我们就从假设检验,ZScore, PValue入手来了解Getis-Ord Gi*统计模型的工作原理。
假设检验
假设检验,它的思想是在总体的分布函数完全未知或只知其形式,但不知参数的情况下,为了推断总体的某些未知特性,提出某些关于总体的假设,然后为假设成立设置一个可以接受的条件(置信度),然后我们就可以通过计算样本均值距离总体均值的偏差程度的概率来拒绝或接受假设。这个解释可能太绕了,举个例子:
“你抬头看看天,然后说”一会儿可能要下雨“,但是心里明白也有可能不下,根据以往的经验大概有90%的把握吧”, 这个过程就体现了上面的思想,在这里:
1,假设条件是:一会儿要下雨;
2,90%把握就是置信度, 是指我们做出假设的信心,这个值越高,代表我们做出假设的把握就越大,推翻假设越难;
3,根据以往的经验,就是历史上导致下雨的条件数据(样本),通过计算样本均值对应总体均值的偏差,我们就可以知道下雨的概率有多高,假设是否成立。
假设检验之所以奏效,其实还有个重要的概念要理解就是中心极限定理。
中心极限定理
中心极限定理的核心思想是,无论当前分布如何,只要有定义良好的均值和标准差,当按照一定的样本空间(每次抽取多少个样本)抽样试验时,随着试验次数的增多,这些均值的频率(均值出现的概率)分布会非常接近正态分布,试验均值和原分布的均值会趋向一致,重采样后的均值方差=原分布方差/样本容量。按照中心极限定理,通过无数次抽样试验后,我们会得到下面的曲线:
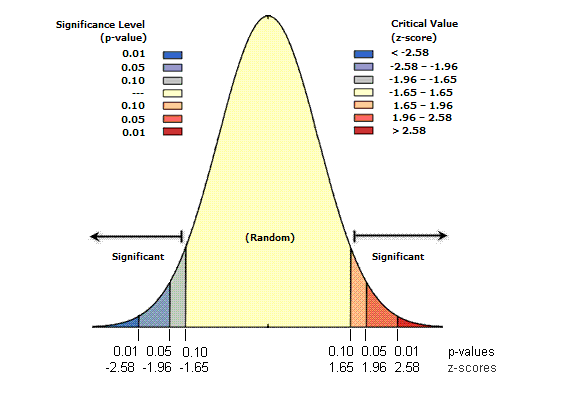
横坐标是每次抽样试验的均值。通过比较样本均值相对总体均值偏移了多少个标准差(z-score),就能知道这个均值出现的概率。这里面涉及了两个重要的指标z-score和p-value:

Z-score是在计算样本均值相对于总体均值偏离了多少个标准差。
p-value 对应的是显著度水平,可以理解为假设明显不成立的概率水平。所以p-value并不是置信区间对应的概率,而是它的补集。Z-Score越大,代表样本偏离假设的程度越大,假设成立的概率越小,当p-value超过置信度临界值,就推翻H0假设。
由于假设试验时,我们并不具备总体样本的真实均值和标准差,是通过样本均值和标准差根据中心极限定理来估计这些值的,所以必定会有误差,置信度反应了我们有多大信心来支撑这样的假设。如果置信度为90%,意味着只要zscore对应的概率<90%,那假设就成立,反之就推翻假设。对应到图上,显著度为0.1, 0.05 ,0.01 对应的置信度换算过来分别为90%, 95%, 99%,置信度越高,代表越确信假设成立,推翻假设越难,从另外一个角度看,一旦推翻,说明确信越高。
有了上面的这些统计推断基础,再回到我们的重点,来探讨Getis-Ord Gi*统计模型。
Getis-Ord Gi*统计模型
Getis-Ord Gi*统计模型正如前面反复强调的,是构建在统计推断试验之上的。对于GIS空间分析来说,我们关心某一要素特征在空间上是否存在随机过程创造的统计显著性空间集聚(热点)或分散(冷点)现象。
基本的逻辑是,按照一定邻域,重新抽样数据,根据本地数据均值相对于总体均值的偏离度,来判断空间分布的随机性是否成立。假设条件就是要素在空间分布上是随机独立分布的,那按照空间加权计算后的结果势必呈现出正态分布。通过计算Zcore来看研究区均值偏离整体均值多远,当超过置信度(比如:90%),就推翻假设,说明要素特征在空间分布上存在统计显著性的聚类或分散,随机分布的假设不成立。
这里,
H0 = 要素特征在空间上是完全随机分布的(CSR),不存在任何空间模式;
p-value是显著度水平,临界值为:0.1, 0.05, 0.01,对应到H0成立的置信度就是90%,95%, 99%。
Gi-bin采用1,2,3对应到置信度90%,95%, 99%,如果:
p-value < 0.1, Gi-bin的值为1;
p-value < 0.05, Gi-bin的值为2;
p-value < 0.01 , Gi-bin的值为3。
看图理解
无论是GA还是ArcMap中的热点分析工具,都遵从了同样的算法原理,下面这张图是针对中国人口分布在ArcMap中做的热点分析结果。
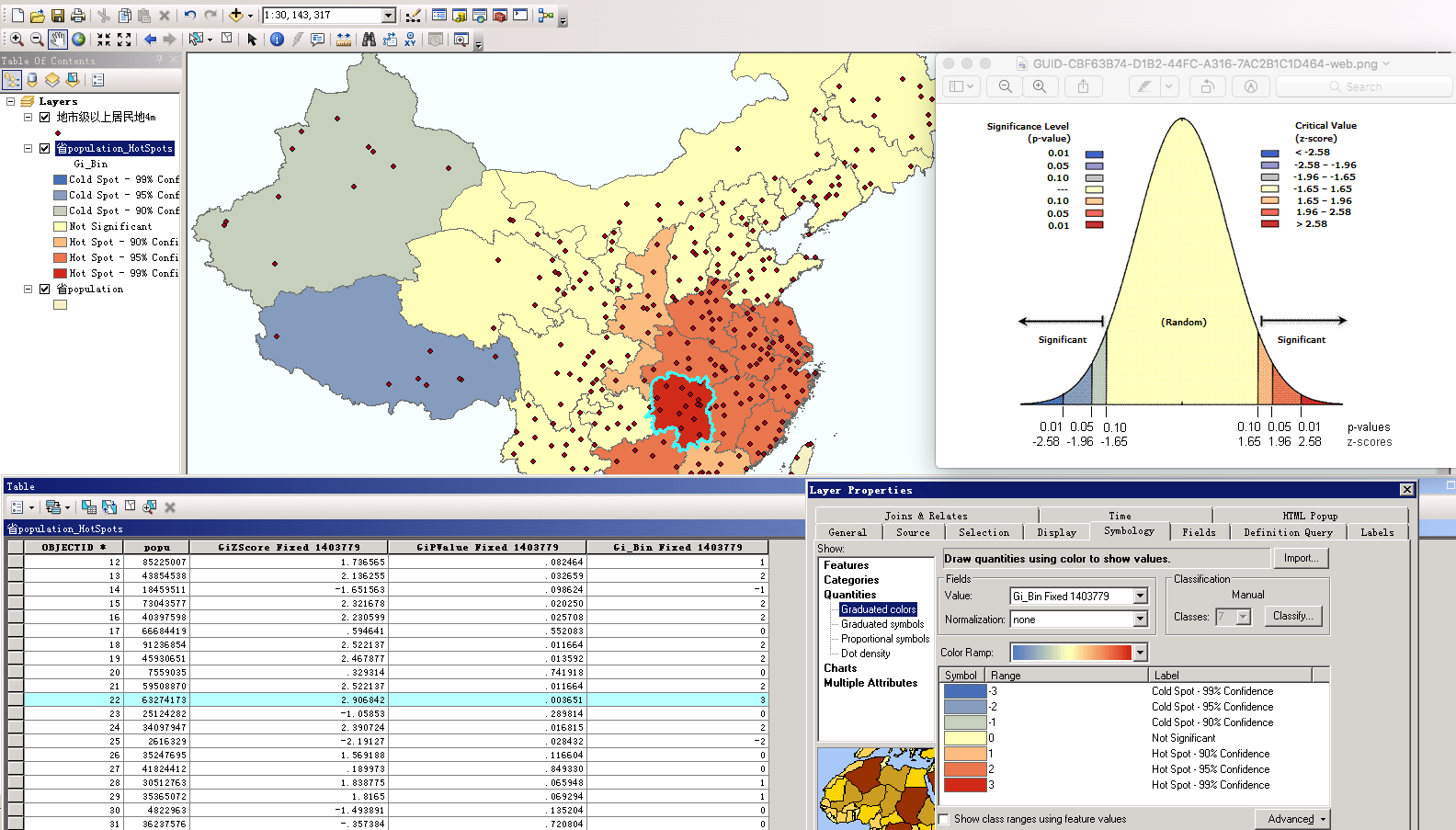
分析结果属性表中包含GiZScore, GiPValue, Gi_Bin三个字段,1403779是邻域区间的大小,单位是米。这个结果是在邻域(半径)为1403779的情况下,以每个输入要素为中心,计算得出的热点分布结果。 默认结果渲染采用Gi_Bin字段,从渲染信息中能看出1,2,3对应了置信度为90%,95%, 99%的高值集聚区,-1,-2,-3对应了90%,95%, 99%的低值分散区。
扩展阅读
Getis-Ord Gi*模型公式推导
Esri官方公布的Gi*计算公式:

公式里面i代表中心要素,j是邻域内的所有要素,Xj代表邻域内第j个要素的属性值,wi,j代表了要素i和j之间的空间距离,n是邻域内的要素总数(相当于样本容量)。
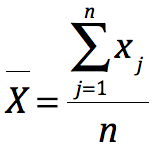
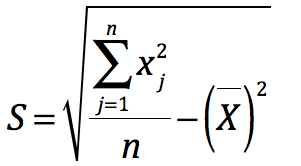
我们来推导化简下看看,Gi*究竟在计算什么,先来看看分母的一大推公式,S显然是要素值的标准差,右边的一大堆变身下:
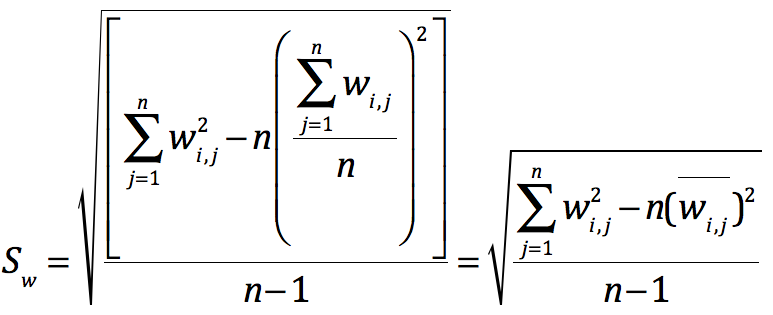
变换下形式,提出一个n,原来它在计算邻域内,所有距离权重的标准差,我用Sw表达,继续化简:
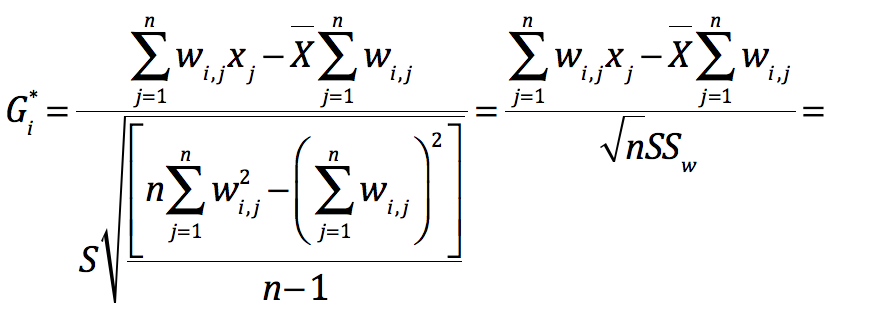

对于正态分布的双变量,双变量的相关系数可以通过如下公式进一步计算:
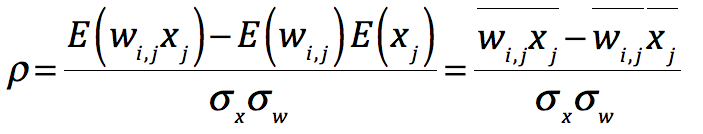
当两个变量完全独立,相关性为0时:
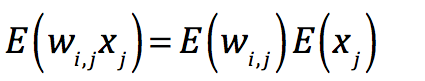
这个形式是否清晰多了?当我们假设H0为要素分布和空间完全无关时,就可以利用上面的公式,根据中心极限定理,用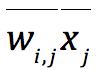 模拟总体均值,
模拟总体均值, 模拟均值分布的标准差,到这里已经可以很清晰的看到
模拟均值分布的标准差,到这里已经可以很清晰的看到
Gi*其实就是ZScore,ZScore越趋向两端,代表距离假设成立的概率越小,当超过显著度,就推翻假设。
参考资料
ArcGIS 官方帮助:
1,Find Hot Spots:http://enterprise.arcgis.com/en/portal/latest/use/geoanalytics-find-hot-spots.htm
2,How Hot Spot Analysis works: http://desktop.arcgis.com/en/arcmap/latest/tools/spatial-statistics-toolbox/h-how-hot-spot-analysis-getis-ord-gi-spatial-stati.htm
3, What is a z-score? What is a p-value?: http://desktop.arcgis.com/en/arcmap/latest/tools/spatial-statistics-toolbox/what-is-a-z-score-what-is-a-p-value.htm
论文:
4,The Analysis of Spatial Association by Use of Distance Statistics: https://onlinelibrary.wiley.com/doi/abs/10.1111/j.1538-4632.1992.tb00261.x
文章来源:https://makeling.github.io/ArcGIS/b2758ce4.html
ArcGIS 作为对GIS研究成果的最佳实践,为我们提供了大量强大、易用的工具,这篇文章就跟大家分享一个构建在统计推断之上的大数据空间模式分析工具——查找热点(Find Hot Spots)。
功能定义
何谓热点?是不是点越密越热?当我们把代表事件的点绘制到地图上,以人类上亿像素的高分辨率双眼和超强大脑,似乎不用工具我们也能看出哪儿密哪儿疏,那为啥还需要分析热点?不会只是为了告诉我们“你看的对”吧?
当然不是,事实上正是因为我们几乎在任何时候都在不自觉的发掘事物的规律和模式,很多时候我们把随机事件解读成了强关联关系,从而导致了决策的失误。对于随机事件呈现的自然规律,不是我们研究的重点,但是如果事件在空间上表现出了强空间关联性,就说明某些空间过程因子正在影响这些事件的发生(此处必有猫腻),这就很重要了,通过获得这些信息:一是我们可以将有限的资源投放到更需要的地方,做到更合理的资源分配,二是通过锁定问题区域,可以进一步发掘背后的关联因子,指导管理。
查找热点工具就是帮助我们实现上述数据挖掘的工具,这里真正关心的是统计意义上的热点和冷点。简单下个定义:“查找热点”是用来发掘数据特征在空间模式上是否存在任何统计显著性聚类的工具。
使用工具
热点工具背后的原理稍复杂,但是使用上非常简单,特别是对大数据分析工具中的查找热点工具,相比桌面中对等的工具要更简单清爽些:
基本工作流,依然遵从三段式:输入-执行分析-输出
输入参数
1, 输入点数据:大数据工具中的查找热点工具目前只支持对点图层的分析,这个点数据应该是代表了某一要素特征的,比如犯罪事件,交通事故等等;
2,设置聚合条柱:聚合条柱用来汇聚输入的点数据到每一个格网,相当于以条柱格网为目标图层,join输入的点数据,实际参与分析计算的是聚合条柱,从这个角度来看,这个工具实质是在针对条柱面图层进行热点分析;
3,设置热点分析的邻域大小:邻域就是分析区,邻域设置的大小要大于聚合条柱,也就是必须要确保一定的统计样本量,过小分析会失败;
4,设置时间步长:这步是可选的,一旦设置了时间步长,分析就会基于每个时间步长内的要素进行分析,如果时间步长过小,那参与的要素数可能低于分析工具要求的最小要素数导致分析失败;
5,设置输出图层名。
6,设置空间参考:既然要用到聚合条柱,聚合条柱是基于投影坐标由程序动态计算的,所以在工具环境变量的设置中,需要设置投影坐标系统,比如我们常用的web_mercator投影3857。
7,最后,还可以选择是否按照当前地图范围分析。
分析过程
从输入的参数和对热点分析工具计算公式了解的基础上,能大致分析出工具背后执行的分析过程;
1,先将点数据按照条柱格网重新聚合为新的待分析图层,每个条柱的count值代表落入的点数,这代表了事件数;
2,以每个条柱格网为中心,按照邻域半径重新划分本地计算分区;
3,按照每个计算分区计算ZScore, PValue和Gi_bin,并将结果以属性的形式附加到聚合条柱图层;
输出结果
查找热点工具的结果以属性字段的形式添加到聚合条柱图层上,添加GiZScore, GiPValue, Gi_Bin三个字段,结果图层渲染默认是以Gi_Bin字段进行唯一值渲染,高值采用偏暖色的红色,低值采用偏冷色的蓝色。
这三个字段都和统计推断的假设检验相关,这三个字段的含义需要在了解计算原理之后才能解释清楚,在此先跳过。但是大家需要清楚热点分析工具的分析目标:是要找出要素特征在空间分布上明显存在统计显著性聚类的区域,也就是ZScore的高值区和低值区。
什么是ZScore, PValue和Gi-bin?接下来我们就来看看工具背后运行的原理。
原理分析
热点分析工具的统计模型是基于 Getis-Ord Gi*统计(读音是G-i-star),先来解释下这个模型名称的由来:
- Getis-Ord:这个模型是构建在前人研究的基础上进一步改进的结果,作者为了表达对前人工作的感谢,将他们的名字作为模型名称的一部分。Arthur Getis is professor of geography at Sun Diego State University.J.K. Ord is the David H. McKinley Professor of Business Administration in the department of management science and information systems at The Pennsylvania State University.
- Gi: 这个模型是构建在经典的G统计和莫兰的I统计之上的,将G统计和I统计联合起来,会发挥更大的威力揭示局部要素空间分布相对于总体的模式特征。
- *:结尾的这个“*”号实际上应该和Gi*连在一起来看,和它对等的是Gi,Gi代表统计的时候不包含中心要素, Gi*代表统计的时候包含中心要素。
热点分析是构建在统计推断中常用的零假设检验的思想之上的。由于我们的眼睛和大脑无时无刻不在分析数据背后的模式,即使是随机分布的事件在空间上也可能表现出某种程度的集聚,热点分析工具的目标就是识别出具有统计显著性聚类的区域,因为这说明这些事件正在受某些空间过程因子的影响,存在空间上的关联性。接下来我们就从假设检验,ZScore, PValue入手来了解Getis-Ord Gi*统计模型的工作原理。
假设检验
假设检验,它的思想是在总体的分布函数完全未知或只知其形式,但不知参数的情况下,为了推断总体的某些未知特性,提出某些关于总体的假设,然后为假设成立设置一个可以接受的条件(置信度),然后我们就可以通过计算样本均值距离总体均值的偏差程度的概率来拒绝或接受假设。这个解释可能太绕了,举个例子:
“你抬头看看天,然后说”一会儿可能要下雨“,但是心里明白也有可能不下,根据以往的经验大概有90%的把握吧”, 这个过程就体现了上面的思想,在这里:
1,假设条件是:一会儿要下雨;
2,90%把握就是置信度, 是指我们做出假设的信心,这个值越高,代表我们做出假设的把握就越大,推翻假设越难;
3,根据以往的经验,就是历史上导致下雨的条件数据(样本),通过计算样本均值对应总体均值的偏差,我们就可以知道下雨的概率有多高,假设是否成立。
假设检验之所以奏效,其实还有个重要的概念要理解就是中心极限定理。
中心极限定理
中心极限定理的核心思想是,无论当前分布如何,只要有定义良好的均值和标准差,当按照一定的样本空间(每次抽取多少个样本)抽样试验时,随着试验次数的增多,这些均值的频率(均值出现的概率)分布会非常接近正态分布,试验均值和原分布的均值会趋向一致,重采样后的均值方差=原分布方差/样本容量。按照中心极限定理,通过无数次抽样试验后,我们会得到下面的曲线:
横坐标是每次抽样试验的均值。通过比较样本均值相对总体均值偏移了多少个标准差(z-score),就能知道这个均值出现的概率。这里面涉及了两个重要的指标z-score和p-value:
Z-score是在计算样本均值相对于总体均值偏离了多少个标准差。
p-value 对应的是显著度水平,可以理解为假设明显不成立的概率水平。所以p-value并不是置信区间对应的概率,而是它的补集。Z-Score越大,代表样本偏离假设的程度越大,假设成立的概率越小,当p-value超过置信度临界值,就推翻H0假设。
由于假设试验时,我们并不具备总体样本的真实均值和标准差,是通过样本均值和标准差根据中心极限定理来估计这些值的,所以必定会有误差,置信度反应了我们有多大信心来支撑这样的假设。如果置信度为90%,意味着只要zscore对应的概率<90%,那假设就成立,反之就推翻假设。对应到图上,显著度为0.1, 0.05 ,0.01 对应的置信度换算过来分别为90%, 95%, 99%,置信度越高,代表越确信假设成立,推翻假设越难,从另外一个角度看,一旦推翻,说明确信越高。
有了上面的这些统计推断基础,再回到我们的重点,来探讨Getis-Ord Gi*统计模型。
Getis-Ord Gi*统计模型
Getis-Ord Gi*统计模型正如前面反复强调的,是构建在统计推断试验之上的。对于GIS空间分析来说,我们关心某一要素特征在空间上是否存在随机过程创造的统计显著性空间集聚(热点)或分散(冷点)现象。
基本的逻辑是,按照一定邻域,重新抽样数据,根据本地数据均值相对于总体均值的偏离度,来判断空间分布的随机性是否成立。假设条件就是要素在空间分布上是随机独立分布的,那按照空间加权计算后的结果势必呈现出正态分布。通过计算Zcore来看研究区均值偏离整体均值多远,当超过置信度(比如:90%),就推翻假设,说明要素特征在空间分布上存在统计显著性的聚类或分散,随机分布的假设不成立。
这里,
H0 = 要素特征在空间上是完全随机分布的(CSR),不存在任何空间模式;
p-value是显著度水平,临界值为:0.1, 0.05, 0.01,对应到H0成立的置信度就是90%,95%, 99%。
Gi-bin采用1,2,3对应到置信度90%,95%, 99%,如果:
p-value < 0.1, Gi-bin的值为1;
p-value < 0.05, Gi-bin的值为2;
p-value < 0.01 , Gi-bin的值为3。
看图理解
无论是GA还是ArcMap中的热点分析工具,都遵从了同样的算法原理,下面这张图是针对中国人口分布在ArcMap中做的热点分析结果。
分析结果属性表中包含GiZScore, GiPValue, Gi_Bin三个字段,1403779是邻域区间的大小,单位是米。这个结果是在邻域(半径)为1403779的情况下,以每个输入要素为中心,计算得出的热点分布结果。 默认结果渲染采用Gi_Bin字段,从渲染信息中能看出1,2,3对应了置信度为90%,95%, 99%的高值集聚区,-1,-2,-3对应了90%,95%, 99%的低值分散区。
扩展阅读
Getis-Ord Gi*模型公式推导
Esri官方公布的Gi*计算公式:
公式里面i代表中心要素,j是邻域内的所有要素,Xj代表邻域内第j个要素的属性值,wi,j代表了要素i和j之间的空间距离,n是邻域内的要素总数(相当于样本容量)。
我们来推导化简下看看,Gi*究竟在计算什么,先来看看分母的一大推公式,S显然是要素值的标准差,右边的一大堆变身下:
变换下形式,提出一个n,原来它在计算邻域内,所有距离权重的标准差,我用Sw表达,继续化简:
对于正态分布的双变量,双变量的相关系数可以通过如下公式进一步计算:
当两个变量完全独立,相关性为0时:
这个形式是否清晰多了?当我们假设H0为要素分布和空间完全无关时,就可以利用上面的公式,根据中心极限定理,用
Gi*其实就是ZScore,ZScore越趋向两端,代表距离假设成立的概率越小,当超过显著度,就推翻假设。
参考资料
ArcGIS 官方帮助:
1,Find Hot Spots:http://enterprise.arcgis.com/en/portal/latest/use/geoanalytics-find-hot-spots.htm
2,How Hot Spot Analysis works: http://desktop.arcgis.com/en/arcmap/latest/tools/spatial-statistics-toolbox/h-how-hot-spot-analysis-getis-ord-gi-spatial-stati.htm
3, What is a z-score? What is a p-value?: http://desktop.arcgis.com/en/arcmap/latest/tools/spatial-statistics-toolbox/what-is-a-z-score-what-is-a-p-value.htm
论文:
4,The Analysis of Spatial Association by Use of Distance Statistics: https://onlinelibrary.wiley.com/doi/abs/10.1111/j.1538-4632.1992.tb00261.x
文章来源:https://makeling.github.io/ArcGIS/b2758ce4.html

