
ArcGIS地理大数据模式识别之密度分析
分享
-
2018-05-17
ArcGIS地理大数据模式识别之密度分析
在基于空间数据的模式分析中,可以通过输入的点要素或某一属性的统计值来计算分布密度,比如通过多年的野外普查,我们已经获得了某一濒危野生动物的统计数据,仅有这些数值,我们无法直观的获得野生动物的分布趋势,通过物种数量来计算物种密度,而后将密度分布再和陆地覆盖数据做对比,就可以用来研究该物种的习性。再比如飞机飞行路径的GPS数据也可以用来做密度分析从而发现哪些飞行区域是高吞吐量的,从而辅助后续航线设计。这一类的分析,都是从数据统计结果进一步获得数据的空间密度分布,因此也叫密度分析。
在ArcGIS 地理大数据分析工具中有一个专门用于上述密度分析的工具——Calculate Density。这篇文章就跟大家分享Calculate Density工具的工作原理。
功能定义
密度计算工具是以要素为核心,计算一定邻域范围内要素的密度。密度分析的结果会以条柱(bin)形式呈现。目前这个输出支持四边形和六边形条柱两种。

从密度计算工具的定义中,我们能梳理出关键的几个要素:
直觉上理解密度计算,就是将原来以点呈现的数据(比如人口),拟合为通过面来呈现连续分布趋势,这样更便于我们发现地理要素特征在空间上的分布规律。
原理分析
任何一个ArcGIS 地理处理工具,就像是一条生产线,送原料进去,加工处理,输出产品。对于密度计算工具来说也不例外,通过前面从功能定义中总结出的四个关键要素,我们能看出要计算密度,需要输入要素,设置搜索半径,选择算法,并可视化结果。接下来我就按照输入、算法、输出三段式来讲解下密度计算工具的原理。
输入
密度分析工具作为长久以来ArcGIS支持的空间模式分析工具,在Desktop 和ArcGIS Pro中我们都可以找到对应的点密度,线密度和核密度分析工具,这意味着密度计算既可以针对点要素,也支持针对线要素进行计算。但是对于大数据工具集中的密度计算工具,目前只支持点要素图层作为输入参数。
限制:大数据密度计算工具目前只支持单独的点要素图层作为输入。
搜索半径,也就是要在多大范围内计算密度,所有落入半径内的要素点,都将参与密度计算。这个搜索半径大小的设置非常重要,直接影响密度分析的结果。设置多大的范围来计算密度最合适呢?这是个深奥的问题,推荐个取巧的办法,可以参考Esri科学家推荐使用的默认搜索半径公式来计算:
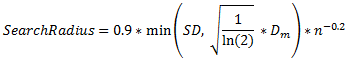
公式中SD代表标准差,Dm是距离中值,n是点数, min是求取二者最小值的方法。这个公式是权衡了标准差和中值距离两个参数,二者取最小值参与最终的计算。在这儿先埋个伏笔,日后我可能会写个自动计算搜索半径的python工具,作为大数据密度分析工具的辅助工具,方便大家使用。其实在桌面核密度计算工具中,这个值是自动计算的,10.2.1之后就是使用了上面的公式。
算法
有了输入的点要素集,设置了搜索半径,那我们就可以以每个点为中心,按照搜索半径生成圆,然后计算落入圆内的所有点,很容易想到单位面积上的点数就是密度啦。最简单的密度计算公式就是:
Density = 所有的事件点总数/圆面积
为何我用事件点呢?是为了区分点要素的point,因为密度计算我们不仅可以针对输入要素点的点数来计算密度,还可以针对点属性表中的统计字段来计算密度,一旦设置了字段,字段值就代表事件点数。当然,如果不指定字段,工具就会按照要素点的点数来计算密度。
密度计算真的这么简单吗?简直不敢相信,其实上面只说了一种密度计算算法,前提是假设了所有事件点在搜索区内均匀分布,这种算法叫""Uniform""算法,中文翻译过来叫“统一”算法。
事实上Uniform算法确实太过简单了,大多数时候,事件分布并不能简单粗暴的按照均匀分布来处理。比如某化工厂发生了污染物泄漏,我们要分析污染物扩散的密度分布图,那显然距离污染源越近,污染物的浓度越高,越远浓度会越低。随着到中心点的距离,影响密度的权重是逐渐衰减的,这种情况,就需要用到核密度分析。
核密度从直觉上理解比从数学公式上理解要容易的多,为了避免把大家绕晕,我就说直觉理解的原理,有刨根问底的同学可以参考扩展阅读部分的解读。
核密度仍然是以要素点为中心,计算搜索半径内点的总数,只是加上了权重,权重随着到中心点的距离逐渐衰减,核的中心点最高,到边缘为0 ,所有权重积分为1。
总结下,大数据工具中的密度计算工具支持两种算法:
输出
经过上面的密度计算,每个搜索区事件点的密度已经计算完成了,接下来就需要可视化这些结果,以帮助我们直观的看出空间事件点的分布模式。
栅格是计算机上展现二维连续分布的常见表达方式。密度分析的结果在ArcGIS Desktop工具中也的确是通过栅格Cell来表达,如果栅格的中心点落入搜索半径内,那栅格中心点所在的密度就赋值给这个栅格像元。如果一个栅格像元被多个分析区覆盖,那这个栅格的值就是所有覆盖它的搜索区密度的叠加。
对于大数据工具来说,输出并不是以栅格的形式表达,而是以bin的形式表达。bin在中文版中翻译成条柱,我们也可以按格网来理解,bin支持四边形和六边形两种格网。在使用工具时,我们可以设置这个格网的大小。

输出格网的大小,决定了生成结果可视化表达的精度。格网越小,密度图绘制出来会越平滑。格网越大,密度图会更粗糙。
高手解读
密度分析算是个比较复杂的工具,为了研究它,我特别请教了ArcGIS空间分析的大牛木工,她深入浅出的通过桌面分析工具,为我厘清了很多乱麻。下面将她的分析过程通过一张图来跟大家分享。
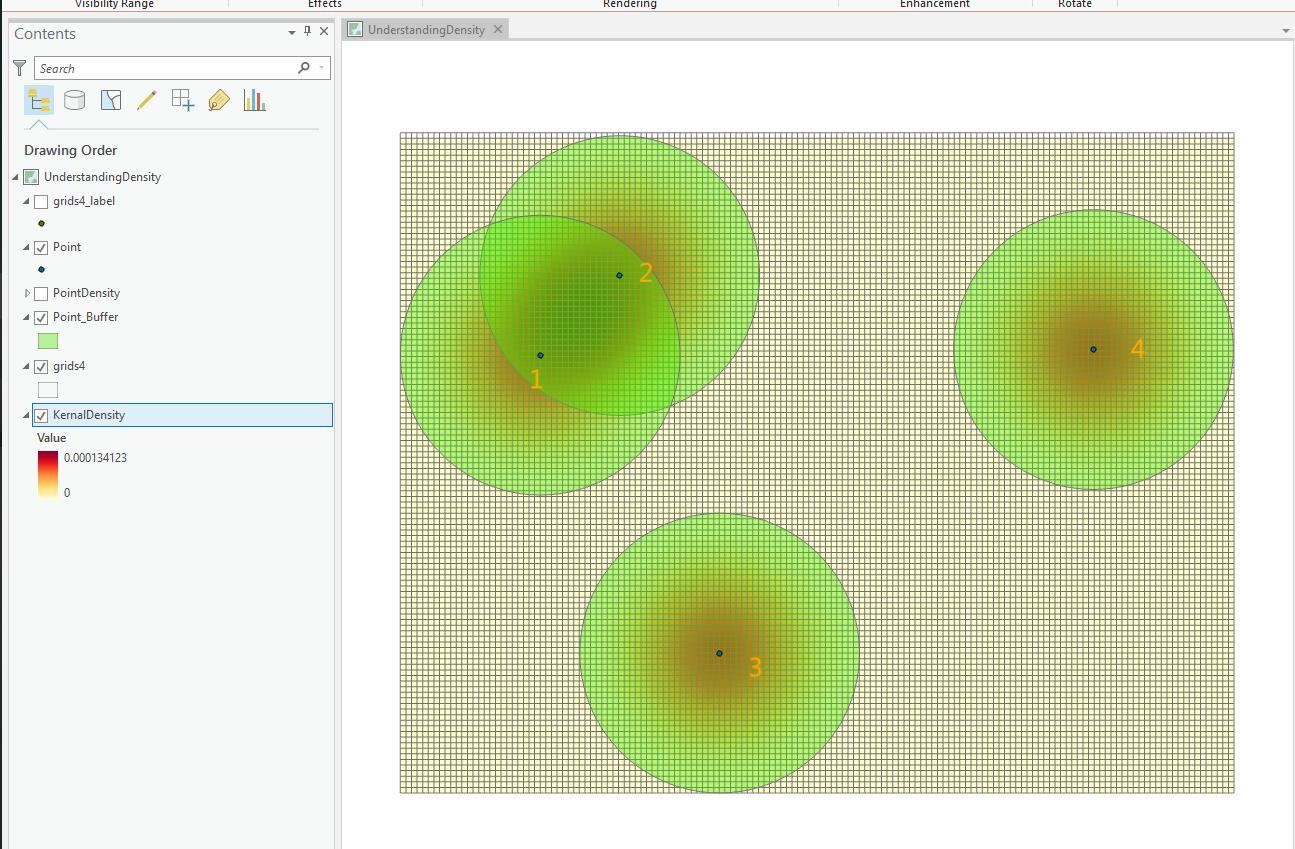
分析过程:
1,生成4个要素点,用来做后面的密度分析(Point);
2,按照搜索半径生成buffer(Point_Buffer),辅助观察密度分析结果;
3, 生成渔网grids4, 用来模拟输出栅格(grid4)像元;
4,通过核密度工具,按照一样的搜索半径,和输出栅格大小,生成KernalDensity图层(KernalDensity)。
从图上我们能看出来对于:
扩展阅读
核密度估计
在统计学中,核密度估计(KDE)是一种无参数估计随机变量的概率密度函数。核密度估计是数据平滑问题的基础,例如基于有限数据样本,推测人口组成。通过一张图直观的体验下核密度:

上面的分布图是对100个正态分布随机变量,采用不同的搜索半径(带宽)进行的核密度估计。灰线代表原始正态分布,蓝线代表搜索半径为0.3的概率密度分布, 绿线代表带宽为0.1的概率密度分布,红线代表带宽为0.05的概率密度分布。从0.3-0.05的带宽变化,我们能看出来带宽越大,核密度越平滑,带宽越小核密度越锐利。
核密度估计公式

在上述公式中:
— K代表核(kernel):是一个非负函数,积分后值为1
— h 是平滑参数:也叫做bandwidth. 在ArcGIS中,这个术语也叫做搜索半径,在知乎上似乎统计学的学生也叫它“窗宽”,为何bandwidth = 窗宽 我不得而知,但是个人感觉带宽或搜索半径理解起来更容易些。
从公式中能看出,影响核密度估计的最重要的两个参数是核函数和bandwidth。 核密度估计就是计算bandwidth范围内, 所有要素到中心点的距离加权(核函数K)叠加后取均值(除n),再除以覆盖的搜索区面积。 接下来再跟大家分享下如何理解核函数和带宽。
核函数
直觉上简单理解核函数就是权重,通过对每个点到中心距离的加权来重新确定分布。在核密度估计中,针对样本空间随机变量的分布性质,可以采用不同的核函数。常用的有uniform, triangular, triweight, Epanechnikov, Quartic, Gaussion, and others。不同的核函数会产生不同的核密度分布结果。
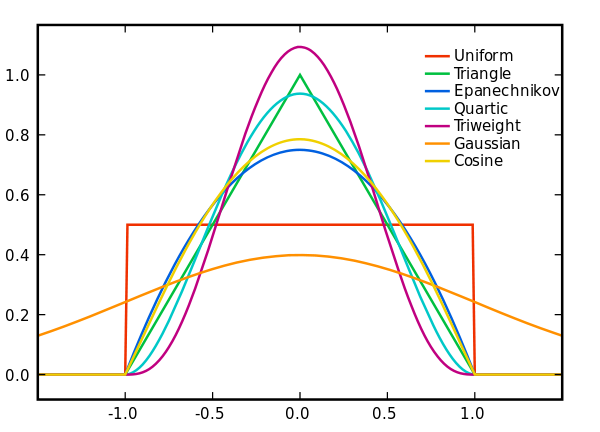
看到这张图?大家是否会想到核函数就是概率密度函数?所以它的积分才会是1,因为所有的概率加在一起就是100%。
核密度估计和直方图非常类似,只是通过核函数赋予了统计结果平滑和连续性。接下来我们通过维基上提供的示例再来直观的理解下核密度估计。
样本点:
x1 = -2.1, x2 = -1.3, x3 = -0.4, x4 = 1.9, x5 = 5.1, x6 = 6.2

直方图密度函数,横轴按照2个单位划分统计区间,这里可以近似的理解为bandwidth, 样本点落入区间,我们就放置一个1/12的箱子,从直方图的高度表达了区间的样本密度。
核密度估计,这里核采用了高斯核(正态分布)函数,方差为2.25。红色虚线表达了每个样本点的高斯分布曲线。 蓝线就是对每条高斯分布曲线的加权叠加统计。
比较上面的两张图,核密度估计相对直方图的离散表达,是一种连续分布的表达,更好的模拟连续随机变量的密度分布。
搜索半径(bandwidth)
核的搜索半径直接影响估计结果。这一点通过上面核密度估计的曲线图我们已经有直观感受。如何选取搜索半径是统计学上的重要研究课题,在前人研究的基础上,针对不同的核函数,有不同的搜索半径计算公式,下面是基于高斯分布的密度估计,带宽是基于最小化均值方差来计算:

正态分布
正态分布又名高斯分布(Gaussian distribution),最早由A.棣莫弗在求二项分布的渐近公式中得到。高斯在研究测量误差时从另一个角度导出了它,因此它也叫高斯分布。正态分布在统计学的许多方面有着重大的影响力, 有大量的随机现象遵循正态分布。我们还是通过正态分布曲线图来直观的感受下它的样子。

正态分布曲线在形态上看起来非常像一口钟,因此它也被形象的称为“钟形分布”。
µ 代表均值或分布期望。
σ 是标准差。
正态分布的概率密度公式:
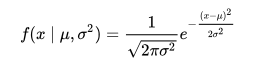
参考资料
ArcGIS官方帮助:http://desktop.arcgis.com/en/arcmap/latest/tools/spatial-analyst-toolbox/how-kernel-density-works.htm
维基百科:https://en.wikipedia.org/wiki/Kernel_density_estimation
维基百科:https://en.wikipedia.org/wiki/Normal_distribution#Definition
文章来源:https://makeling.github.io/ArcGIS/8c3d7b25.html
在基于空间数据的模式分析中,可以通过输入的点要素或某一属性的统计值来计算分布密度,比如通过多年的野外普查,我们已经获得了某一濒危野生动物的统计数据,仅有这些数值,我们无法直观的获得野生动物的分布趋势,通过物种数量来计算物种密度,而后将密度分布再和陆地覆盖数据做对比,就可以用来研究该物种的习性。再比如飞机飞行路径的GPS数据也可以用来做密度分析从而发现哪些飞行区域是高吞吐量的,从而辅助后续航线设计。这一类的分析,都是从数据统计结果进一步获得数据的空间密度分布,因此也叫密度分析。
在ArcGIS 地理大数据分析工具中有一个专门用于上述密度分析的工具——Calculate Density。这篇文章就跟大家分享Calculate Density工具的工作原理。
功能定义
密度计算工具是以要素为核心,计算一定邻域范围内要素的密度。密度分析的结果会以条柱(bin)形式呈现。目前这个输出支持四边形和六边形条柱两种。
从密度计算工具的定义中,我们能梳理出关键的几个要素:
- 针对输入要素
- 在一定范围区间(搜索半径)
- 按某种算法计算密度
- 结果以栅格格网呈现(bin)。
直觉上理解密度计算,就是将原来以点呈现的数据(比如人口),拟合为通过面来呈现连续分布趋势,这样更便于我们发现地理要素特征在空间上的分布规律。
原理分析
任何一个ArcGIS 地理处理工具,就像是一条生产线,送原料进去,加工处理,输出产品。对于密度计算工具来说也不例外,通过前面从功能定义中总结出的四个关键要素,我们能看出要计算密度,需要输入要素,设置搜索半径,选择算法,并可视化结果。接下来我就按照输入、算法、输出三段式来讲解下密度计算工具的原理。
输入
- 输入图层
密度分析工具作为长久以来ArcGIS支持的空间模式分析工具,在Desktop 和ArcGIS Pro中我们都可以找到对应的点密度,线密度和核密度分析工具,这意味着密度计算既可以针对点要素,也支持针对线要素进行计算。但是对于大数据工具集中的密度计算工具,目前只支持点要素图层作为输入参数。
限制:大数据密度计算工具目前只支持单独的点要素图层作为输入。
- 搜索半径(bandwidth)
搜索半径,也就是要在多大范围内计算密度,所有落入半径内的要素点,都将参与密度计算。这个搜索半径大小的设置非常重要,直接影响密度分析的结果。设置多大的范围来计算密度最合适呢?这是个深奥的问题,推荐个取巧的办法,可以参考Esri科学家推荐使用的默认搜索半径公式来计算:
公式中SD代表标准差,Dm是距离中值,n是点数, min是求取二者最小值的方法。这个公式是权衡了标准差和中值距离两个参数,二者取最小值参与最终的计算。在这儿先埋个伏笔,日后我可能会写个自动计算搜索半径的python工具,作为大数据密度分析工具的辅助工具,方便大家使用。其实在桌面核密度计算工具中,这个值是自动计算的,10.2.1之后就是使用了上面的公式。
算法
有了输入的点要素集,设置了搜索半径,那我们就可以以每个点为中心,按照搜索半径生成圆,然后计算落入圆内的所有点,很容易想到单位面积上的点数就是密度啦。最简单的密度计算公式就是:
Density = 所有的事件点总数/圆面积
为何我用事件点呢?是为了区分点要素的point,因为密度计算我们不仅可以针对输入要素点的点数来计算密度,还可以针对点属性表中的统计字段来计算密度,一旦设置了字段,字段值就代表事件点数。当然,如果不指定字段,工具就会按照要素点的点数来计算密度。
密度计算真的这么简单吗?简直不敢相信,其实上面只说了一种密度计算算法,前提是假设了所有事件点在搜索区内均匀分布,这种算法叫""Uniform""算法,中文翻译过来叫“统一”算法。
事实上Uniform算法确实太过简单了,大多数时候,事件分布并不能简单粗暴的按照均匀分布来处理。比如某化工厂发生了污染物泄漏,我们要分析污染物扩散的密度分布图,那显然距离污染源越近,污染物的浓度越高,越远浓度会越低。随着到中心点的距离,影响密度的权重是逐渐衰减的,这种情况,就需要用到核密度分析。
核密度从直觉上理解比从数学公式上理解要容易的多,为了避免把大家绕晕,我就说直觉理解的原理,有刨根问底的同学可以参考扩展阅读部分的解读。
核密度仍然是以要素点为中心,计算搜索半径内点的总数,只是加上了权重,权重随着到中心点的距离逐渐衰减,核的中心点最高,到边缘为0 ,所有权重积分为1。
总结下,大数据工具中的密度计算工具支持两种算法:
- Uniform(统一): 计算单位面积的量值,相当于事件点在搜索区均匀分布
- Kernel(核): 应用核函数(权重)将事件点拟合为锥形平面。
输出
经过上面的密度计算,每个搜索区事件点的密度已经计算完成了,接下来就需要可视化这些结果,以帮助我们直观的看出空间事件点的分布模式。
栅格是计算机上展现二维连续分布的常见表达方式。密度分析的结果在ArcGIS Desktop工具中也的确是通过栅格Cell来表达,如果栅格的中心点落入搜索半径内,那栅格中心点所在的密度就赋值给这个栅格像元。如果一个栅格像元被多个分析区覆盖,那这个栅格的值就是所有覆盖它的搜索区密度的叠加。
对于大数据工具来说,输出并不是以栅格的形式表达,而是以bin的形式表达。bin在中文版中翻译成条柱,我们也可以按格网来理解,bin支持四边形和六边形两种格网。在使用工具时,我们可以设置这个格网的大小。
- 对于四边形: size = 边长
- 对于六边形: size = 六边形的高
输出格网的大小,决定了生成结果可视化表达的精度。格网越小,密度图绘制出来会越平滑。格网越大,密度图会更粗糙。
高手解读
密度分析算是个比较复杂的工具,为了研究它,我特别请教了ArcGIS空间分析的大牛木工,她深入浅出的通过桌面分析工具,为我厘清了很多乱麻。下面将她的分析过程通过一张图来跟大家分享。
分析过程:
1,生成4个要素点,用来做后面的密度分析(Point);
2,按照搜索半径生成buffer(Point_Buffer),辅助观察密度分析结果;
3, 生成渔网grids4, 用来模拟输出栅格(grid4)像元;
4,通过核密度工具,按照一样的搜索半径,和输出栅格大小,生成KernalDensity图层(KernalDensity)。
从图上我们能看出来对于:
- 分析区只有一个点的3,4 , 核密度输出呈现同心圆的方式逐渐衰减,到边界处为0,这正是核函数作用的结果。
- 1,2 两个点的分析区存在叠加,所以叠加区的栅格像元值会累加,密度最大。
扩展阅读
核密度估计
在统计学中,核密度估计(KDE)是一种无参数估计随机变量的概率密度函数。核密度估计是数据平滑问题的基础,例如基于有限数据样本,推测人口组成。通过一张图直观的体验下核密度:
上面的分布图是对100个正态分布随机变量,采用不同的搜索半径(带宽)进行的核密度估计。灰线代表原始正态分布,蓝线代表搜索半径为0.3的概率密度分布, 绿线代表带宽为0.1的概率密度分布,红线代表带宽为0.05的概率密度分布。从0.3-0.05的带宽变化,我们能看出来带宽越大,核密度越平滑,带宽越小核密度越锐利。
核密度估计公式
在上述公式中:
— K代表核(kernel):是一个非负函数,积分后值为1
— h 是平滑参数:也叫做bandwidth. 在ArcGIS中,这个术语也叫做搜索半径,在知乎上似乎统计学的学生也叫它“窗宽”,为何bandwidth = 窗宽 我不得而知,但是个人感觉带宽或搜索半径理解起来更容易些。
从公式中能看出,影响核密度估计的最重要的两个参数是核函数和bandwidth。 核密度估计就是计算bandwidth范围内, 所有要素到中心点的距离加权(核函数K)叠加后取均值(除n),再除以覆盖的搜索区面积。 接下来再跟大家分享下如何理解核函数和带宽。
核函数
直觉上简单理解核函数就是权重,通过对每个点到中心距离的加权来重新确定分布。在核密度估计中,针对样本空间随机变量的分布性质,可以采用不同的核函数。常用的有uniform, triangular, triweight, Epanechnikov, Quartic, Gaussion, and others。不同的核函数会产生不同的核密度分布结果。
看到这张图?大家是否会想到核函数就是概率密度函数?所以它的积分才会是1,因为所有的概率加在一起就是100%。
核密度估计和直方图非常类似,只是通过核函数赋予了统计结果平滑和连续性。接下来我们通过维基上提供的示例再来直观的理解下核密度估计。
样本点:
x1 = -2.1, x2 = -1.3, x3 = -0.4, x4 = 1.9, x5 = 5.1, x6 = 6.2
直方图密度函数,横轴按照2个单位划分统计区间,这里可以近似的理解为bandwidth, 样本点落入区间,我们就放置一个1/12的箱子,从直方图的高度表达了区间的样本密度。
核密度估计,这里核采用了高斯核(正态分布)函数,方差为2.25。红色虚线表达了每个样本点的高斯分布曲线。 蓝线就是对每条高斯分布曲线的加权叠加统计。
比较上面的两张图,核密度估计相对直方图的离散表达,是一种连续分布的表达,更好的模拟连续随机变量的密度分布。
搜索半径(bandwidth)
核的搜索半径直接影响估计结果。这一点通过上面核密度估计的曲线图我们已经有直观感受。如何选取搜索半径是统计学上的重要研究课题,在前人研究的基础上,针对不同的核函数,有不同的搜索半径计算公式,下面是基于高斯分布的密度估计,带宽是基于最小化均值方差来计算:
正态分布
正态分布又名高斯分布(Gaussian distribution),最早由A.棣莫弗在求二项分布的渐近公式中得到。高斯在研究测量误差时从另一个角度导出了它,因此它也叫高斯分布。正态分布在统计学的许多方面有着重大的影响力, 有大量的随机现象遵循正态分布。我们还是通过正态分布曲线图来直观的感受下它的样子。
正态分布曲线在形态上看起来非常像一口钟,因此它也被形象的称为“钟形分布”。
µ 代表均值或分布期望。
σ 是标准差。
正态分布的概率密度公式:
参考资料
ArcGIS官方帮助:http://desktop.arcgis.com/en/arcmap/latest/tools/spatial-analyst-toolbox/how-kernel-density-works.htm
维基百科:https://en.wikipedia.org/wiki/Kernel_density_estimation
维基百科:https://en.wikipedia.org/wiki/Normal_distribution#Definition
文章来源:https://makeling.github.io/ArcGIS/8c3d7b25.html

