
ArcGIS Pro 2.1中的新集群工具:让机器学习触手可及
分享
-
2018-01-26
随着Pro 2.1的发布,您现在在空间统计工具箱中拥有了3个强大的新型集群工具,可以帮助您以新的方式查找模式并理解数据。一个聚类算法究竟做了什么?它根据位置(仅空间分量),值(仅属性)或位置和值的组合来查找自然子集或要素分组。聚类算法是一种无监督的机器学习,这意味着你不必定义什么是预先成为一个聚类的意思(通常称为训练模型)。相反,该算法通过评估数据并找到存在的自然模式来为您做到这一点。
在点数据中寻找隐藏的模式
为什么?
直观地查找点数据中的模式可能很快变得困难,特别是随着我们的数据集越来越大。一年的犯罪事件或交通事故的数量可能在几十到几十万之间,重叠点隐藏了我们数据中的实际模式。使用基于密度的聚类工具可以通过查看地图上的数据点来显示难以看到的模式。
什么数据?
当您在点数据中查找群集时,将使用基于密度的群集。具有管道破裂数据的城市供水设施可以创建群集来定位易发生问题的区域。有点数据显示射门得分的位置的教练可以决定最佳射门位置。地震数据可以用来创建划分断层带的集群。如果您的重点是点数据的空间模式,基于密度的聚类方法可能就是您正在寻找的。
它是如何工作的?
基于密度的聚类工具使用无监督的机器学习算法来确定点特征集中的区域以及由空区域或稀疏区域分隔的区域。有三种算法为基于密度的聚类工具提供动力:1)定义距离(DBScan),2)自我调整(HDBScan)和3)多尺度(OPTICS)。这些算法在所有方面都有所不同,根据分析和您的需求,提供了不同级别的可定制性。我们建议阅读更多关于他们如何工作和试验的信息,看看哪种方法最适合您的分析。根据所选的方法,工具还会输出强大的图表,以帮助您了解群集成员以及如何选择群集成员。
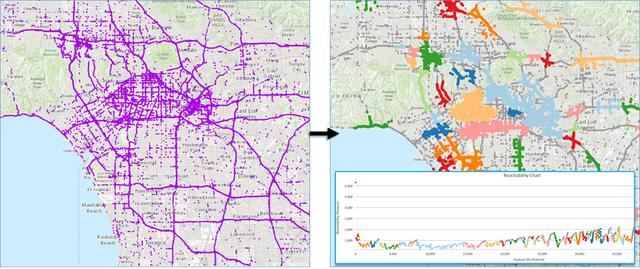
使用基于密度的聚类和OPTICS算法,通过洛杉矶地区的Waze对交通警报进行聚类和探索
利用您的属性数据与多元聚类
为什么?
当您的数据包含的信息不仅仅是位置时,多元聚类工具可让您解锁属性数据。我们所访问的大部分数据都具有有价值的属性信息,但即使是少数变量也可能难以可视化和解释模式。使用多变量聚类工具可以将变量输入到算法中,以创建成员具有相似值的聚类。根据您的数据和分析的需要,你可以选择在空间受限或无空间该工具的版本。还可以为分析设置可选的约束参数,使您可以创建特定大小的群集或高于或低于截止阈值的值。如果这听起来很熟悉,那么您可能已经使用了分组分析工具 - 新的多变量聚类工具构建并向分组分析方法添加新功能。
什么数据?
有多种应用程序可以应用多变量聚类,并且可以同时处理点和多边形数据。普查数据是多变量聚类的重要候选者,因为它具有如此多的属性。除了基于多个属性对人口普查数据进行聚类之外,您还可以创建人口最少或家庭收入最高的聚类。结合购买模式和人口特征的客户数据可以帮助您定位下一个销售活动。环境数据,如土壤或水的地球化学样本,可用于发现污染群或您的下一个勘探目标。
它是如何工作的?
空间约束多变量聚类是SKATER算法的一个实现,通过增长和修剪最小生成树来创建相似的聚类。在此了解有关SKATER背后算法的更多信息。多变量聚类是k-means ++算法的一个实现,它对特征进行分割,使得在聚类内差异最小化。
这些工具还充分利用Pro内置的图表引擎。在运行任一多变量聚类工具之后,会生成一个交互框图,通过探索数据的分布以及每个聚类如何适应,帮助您深入挖掘结果并更好地了解每个聚类的特征。

使用空间约束多变量聚类创建基于水样的氧,硝酸盐,磷酸盐和盐度读数的空间受限簇。箱形图有助于探索聚类,并查看与整个数据集相比的平均聚类值。
我们希望这些强大的平易近人的机器学习技术将有助于解开数据中隐藏的模式。留意博客和案例研究,在接下来的几个月中重点介绍这些新工具。
在点数据中寻找隐藏的模式
为什么?
直观地查找点数据中的模式可能很快变得困难,特别是随着我们的数据集越来越大。一年的犯罪事件或交通事故的数量可能在几十到几十万之间,重叠点隐藏了我们数据中的实际模式。使用基于密度的聚类工具可以通过查看地图上的数据点来显示难以看到的模式。
什么数据?
当您在点数据中查找群集时,将使用基于密度的群集。具有管道破裂数据的城市供水设施可以创建群集来定位易发生问题的区域。有点数据显示射门得分的位置的教练可以决定最佳射门位置。地震数据可以用来创建划分断层带的集群。如果您的重点是点数据的空间模式,基于密度的聚类方法可能就是您正在寻找的。
它是如何工作的?
基于密度的聚类工具使用无监督的机器学习算法来确定点特征集中的区域以及由空区域或稀疏区域分隔的区域。有三种算法为基于密度的聚类工具提供动力:1)定义距离(DBScan),2)自我调整(HDBScan)和3)多尺度(OPTICS)。这些算法在所有方面都有所不同,根据分析和您的需求,提供了不同级别的可定制性。我们建议阅读更多关于他们如何工作和试验的信息,看看哪种方法最适合您的分析。根据所选的方法,工具还会输出强大的图表,以帮助您了解群集成员以及如何选择群集成员。
使用基于密度的聚类和OPTICS算法,通过洛杉矶地区的Waze对交通警报进行聚类和探索
利用您的属性数据与多元聚类
为什么?
当您的数据包含的信息不仅仅是位置时,多元聚类工具可让您解锁属性数据。我们所访问的大部分数据都具有有价值的属性信息,但即使是少数变量也可能难以可视化和解释模式。使用多变量聚类工具可以将变量输入到算法中,以创建成员具有相似值的聚类。根据您的数据和分析的需要,你可以选择在空间受限或无空间该工具的版本。还可以为分析设置可选的约束参数,使您可以创建特定大小的群集或高于或低于截止阈值的值。如果这听起来很熟悉,那么您可能已经使用了分组分析工具 - 新的多变量聚类工具构建并向分组分析方法添加新功能。
什么数据?
有多种应用程序可以应用多变量聚类,并且可以同时处理点和多边形数据。普查数据是多变量聚类的重要候选者,因为它具有如此多的属性。除了基于多个属性对人口普查数据进行聚类之外,您还可以创建人口最少或家庭收入最高的聚类。结合购买模式和人口特征的客户数据可以帮助您定位下一个销售活动。环境数据,如土壤或水的地球化学样本,可用于发现污染群或您的下一个勘探目标。
它是如何工作的?
空间约束多变量聚类是SKATER算法的一个实现,通过增长和修剪最小生成树来创建相似的聚类。在此了解有关SKATER背后算法的更多信息。多变量聚类是k-means ++算法的一个实现,它对特征进行分割,使得在聚类内差异最小化。
这些工具还充分利用Pro内置的图表引擎。在运行任一多变量聚类工具之后,会生成一个交互框图,通过探索数据的分布以及每个聚类如何适应,帮助您深入挖掘结果并更好地了解每个聚类的特征。
使用空间约束多变量聚类创建基于水样的氧,硝酸盐,磷酸盐和盐度读数的空间受限簇。箱形图有助于探索聚类,并查看与整个数据集相比的平均聚类值。
我们希望这些强大的平易近人的机器学习技术将有助于解开数据中隐藏的模式。留意博客和案例研究,在接下来的几个月中重点介绍这些新工具。
1 个评论
这个很强大,但是看上去挺复杂

