
白话空间统计之二十五:空间权重矩阵(四)R语言中的空间权重矩阵(5)完结篇:自然临近关系
分享
-
2017-11-16
自然临近是R语言中spdep中内置的最后一种临近关系。
所谓的自然临近,指的是不进行任何的预设关系,通过其空间位置来判断是否属于相互临近,那么这个空间位置指的是什么呢?众所周知,在几何图形中,三角形是最稳定的一种结构,而以TIN(不规则三角网)为主要结构的地形结构数字化表达,在地理上也有非常广泛的应用。
那么这个自然临域关系,用的也是三角网的方式来进行划分的。
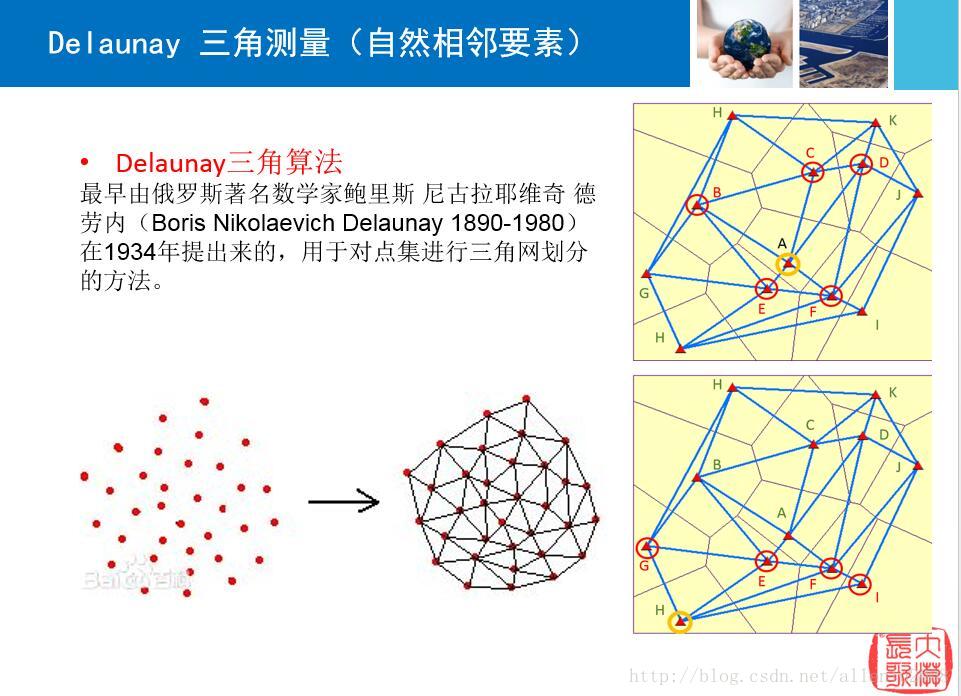
自然相邻要素的原理,就是将所有的点构造为狄罗尼三角网,然后如果两个点之间,共有一个三角形,那么就认为两个点是相邻的关系,在spdep里面,内置了这种空间关系的算法,下面来还是用中国的省会点要素,来看看自然临域关系:
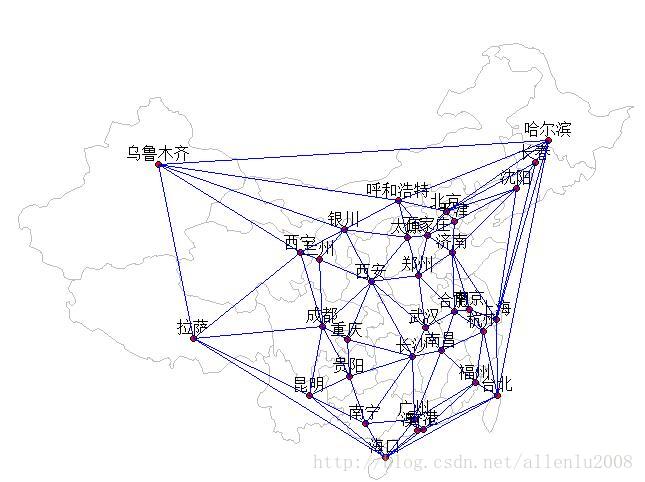
定义语句如下:
library("sp")
library("maptools")
library("spdep")
path <- "E:\\workspace\\IDE\\Rworkspace\\空间分析\\空间权重矩阵\\china\\"
#将中国的省级行政区划读取为ploygon,省会读取成point
cnData <- readShapePoly(paste(path,"CNPG_S.shp",sep =""))
ctData <- readShapePoints(paste(path,"city_SH.shp",sep =""))
#定义投影为wgs84
proj4string(cnData) <- "+proj=longlat +datum=WGS84"
proj4string(ctData) <- "+proj=longlat +datum=WGS84"
#定义唯一标识符,用行政区划的编码
IDs <- ctData@data$ADCODE99
#将名称转换为gbk编码
ctData$NAME <- iconv(ctData$NAME,"UTF-8","GBK")
plot(cnData,border="grey")
plot(ctData,pch=19,cex=1,col='red',add=T)
text(ctData@coords[,1],ctData@coords[,2]+1,labels = ctData$NAME)
#自然临域空间关系
t_nb <- tri2nb(ctData@coords,row.names = IDs)
plot(nb2listw(t_nb),ctData@coords,col='blue',add=T)
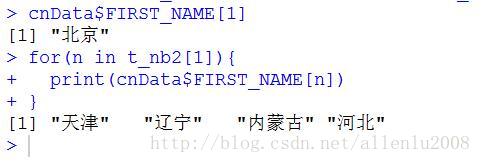
定义完成之后,我们来看看北京的自然领域有哪些城市:

自然临域关系无法向其他关系的那样,增加限定条件或者扩大范围,他就是默认按照空间的位置进行设定的,所以只要不改变空间位置,关系基本上就不会改变了……无任何参数可以设定。
自然临域因为狄罗尼三角网的构造算法,一定会以凸多边形为封闭,所以有些位置的构造会形成巨大的跨越,比如最外面的几个点,乌鲁木齐——哈尔滨——台北——海口——拉萨会形成一个封闭的凸多边形,所以可能造成极远位置被设置为临近关系的情况出现,这样就需要通过人工的关系进行处理了。
如同K临近一样,这种关系也可以作用在面要素上,而因为它用的点要素,所以依然采用的是几何质心来进行设定,如下:
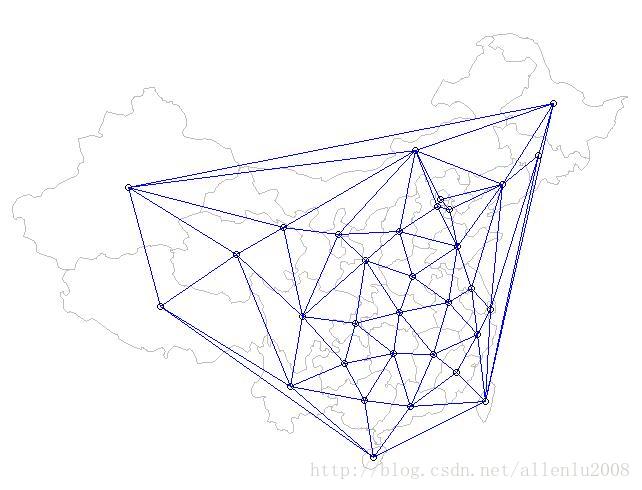
定义语句如下:
t_nb2 <- tri2nb(coordinates(cnData),row.names = cnData$Code)
plot(cnData,border="grey")
plot(nb2listw(t_nb2),coordinates(cnData),col='blue',add=T)
但是通过面要素的质心来实现的,结果与使用省会的位置不一致,所以结果也是不同的,比如北京的临近要素:
那么实在实际的应用中,到底用省会来进行定义,还是用省面质心来进行定义,就仁者见仁智者见智了。
通常来说,如果是偏向经济、社会关系和政策方面的研究,使用省会进行定义关系比较合理,而偏向资源和地理空间方面的研究,用省域面进行定义比较合理。
当然还有一些主要是点状要素为主要空间载体的研究,比如学校的教育资源、交通事故高发位置、商圈购物点、酒店、医院等等的空间分布研究,那么建议使用自然临域关系比使用K临接关系要更好。
当然,默认的关系可以通过自定义的方式,来进行调整,调整之后可能会更加接近真实的研究状况。
好了,到此为止R语言spdep包的空间权重矩阵内置方法就讲完了,因为R语言的开源特性,它还支持对geoda的gal、gwt格式的空间权重矩阵文档的读取,这个方法大家自行去了解,我这里就不多说了。
最后做个总结:
1、R语言里面的spdep包支持四种默认的空间关系定义,分别是:共边相邻(rook' case),共点共边相邻(queen's case),K临近(K nearest neighbours)和自然临近(狄罗尼三角网临近)。 PS:当然,还有一种网格临近(cell2nb),这种一般在矢量数据里面很少存在,我就不说了。 2、spdep还支持利用距离函数来定义不同的权重,但是需要在定义了空间关系的情况下再使用。 3、如果对于默认的关系不满意,还可以自行定义空间关系。 4、空间关系可以不同类型的数据进行传递,如果有对应的唯一标识符,可以直接转换,如果没有,则需要但是需要自己写算法实现。直接转换的方法使用最简单排序即可。代码最后给出。 5、空间关系的选择没有一劳永逸的方法,需要根据研究的内容不断进行探索。
最后给出空间关系传统的方法:
首先两份数据,省会城市的点数据和省域面数据,其中,省会城市的点数据中有一列就是省域面数据的省级行政编码:

我们所要做的,就是同时对这两个空间数据框的这个一个列,进行排序即可,然后就可以进行自由传递了,如下所示:

代码实现如下
library("sp")
library("maptools")
library("spdep")
path <- "E:\\workspace\\IDE\\Rworkspace\\空间分析\\空间权重矩阵\\china\\"
#将中国的省级行政区划读取为ploygon,省会读取成point
cnData <- readShapePoly(paste(path,"CNPG_S.shp",sep =""))
ctData <- readShapePoints(paste(path,"city_SH.shp",sep =""))
cnData$FIRST_NAME <- iconv(cnData$FIRST_NAME,"UTF-8","GBK")
ctData$NAME <- iconv(ctData$NAME,"UTF-8","GBK")
#定义投影为wgs84
proj4string(cnData) <- "+proj=longlat +datum=WGS84"
proj4string(ctData) <- "+proj=longlat +datum=WGS84"
#同时利用同一字段排序即可实现传递
cnData <-cnData[order(cnData@data$Code),]
ctData <- ctData[order(ctData@data$S_CODE),]
ctIDs <- ctData$S_CODE
cnIDs <- cnData$Code
w_rn1 <- tri2nb(coordinates(ctData),row.names = ctIDs)
par(mfrow=c(2,1),mar=c(0,0,1,0))
plot(ctData,pch=19,cex=1,col='red')
text(ctData@coords[,1],ctData@coords[,2]+1,labels = ctData$NAME)
plot(nb2listw(w_rn1),coordinates(ctData),add=T)
title("省会点数据自然临近关系")
plot(cnData,border="grey")
plot(nb2listw(w_rn1),coordinates(cnData),add=T)
title("省会点数据自然临近关系传递")
文章来源:http://blog.csdn.net/allenlu2008/article/details/78166248
所谓的自然临近,指的是不进行任何的预设关系,通过其空间位置来判断是否属于相互临近,那么这个空间位置指的是什么呢?众所周知,在几何图形中,三角形是最稳定的一种结构,而以TIN(不规则三角网)为主要结构的地形结构数字化表达,在地理上也有非常广泛的应用。
那么这个自然临域关系,用的也是三角网的方式来进行划分的。
自然相邻要素的原理,就是将所有的点构造为狄罗尼三角网,然后如果两个点之间,共有一个三角形,那么就认为两个点是相邻的关系,在spdep里面,内置了这种空间关系的算法,下面来还是用中国的省会点要素,来看看自然临域关系:
定义语句如下:
library("sp")
library("maptools")
library("spdep")
path <- "E:\\workspace\\IDE\\Rworkspace\\空间分析\\空间权重矩阵\\china\\"
#将中国的省级行政区划读取为ploygon,省会读取成point
cnData <- readShapePoly(paste(path,"CNPG_S.shp",sep =""))
ctData <- readShapePoints(paste(path,"city_SH.shp",sep =""))
#定义投影为wgs84
proj4string(cnData) <- "+proj=longlat +datum=WGS84"
proj4string(ctData) <- "+proj=longlat +datum=WGS84"
#定义唯一标识符,用行政区划的编码
IDs <- ctData@data$ADCODE99
#将名称转换为gbk编码
ctData$NAME <- iconv(ctData$NAME,"UTF-8","GBK")
plot(cnData,border="grey")
plot(ctData,pch=19,cex=1,col='red',add=T)
text(ctData@coords[,1],ctData@coords[,2]+1,labels = ctData$NAME)
#自然临域空间关系
t_nb <- tri2nb(ctData@coords,row.names = IDs)
plot(nb2listw(t_nb),ctData@coords,col='blue',add=T)
定义完成之后,我们来看看北京的自然领域有哪些城市:
自然临域关系无法向其他关系的那样,增加限定条件或者扩大范围,他就是默认按照空间的位置进行设定的,所以只要不改变空间位置,关系基本上就不会改变了……无任何参数可以设定。
自然临域因为狄罗尼三角网的构造算法,一定会以凸多边形为封闭,所以有些位置的构造会形成巨大的跨越,比如最外面的几个点,乌鲁木齐——哈尔滨——台北——海口——拉萨会形成一个封闭的凸多边形,所以可能造成极远位置被设置为临近关系的情况出现,这样就需要通过人工的关系进行处理了。
如同K临近一样,这种关系也可以作用在面要素上,而因为它用的点要素,所以依然采用的是几何质心来进行设定,如下:
定义语句如下:
t_nb2 <- tri2nb(coordinates(cnData),row.names = cnData$Code)
plot(cnData,border="grey")
plot(nb2listw(t_nb2),coordinates(cnData),col='blue',add=T)
但是通过面要素的质心来实现的,结果与使用省会的位置不一致,所以结果也是不同的,比如北京的临近要素:
那么实在实际的应用中,到底用省会来进行定义,还是用省面质心来进行定义,就仁者见仁智者见智了。
通常来说,如果是偏向经济、社会关系和政策方面的研究,使用省会进行定义关系比较合理,而偏向资源和地理空间方面的研究,用省域面进行定义比较合理。
当然还有一些主要是点状要素为主要空间载体的研究,比如学校的教育资源、交通事故高发位置、商圈购物点、酒店、医院等等的空间分布研究,那么建议使用自然临域关系比使用K临接关系要更好。
当然,默认的关系可以通过自定义的方式,来进行调整,调整之后可能会更加接近真实的研究状况。
好了,到此为止R语言spdep包的空间权重矩阵内置方法就讲完了,因为R语言的开源特性,它还支持对geoda的gal、gwt格式的空间权重矩阵文档的读取,这个方法大家自行去了解,我这里就不多说了。
最后做个总结:
1、R语言里面的spdep包支持四种默认的空间关系定义,分别是:共边相邻(rook' case),共点共边相邻(queen's case),K临近(K nearest neighbours)和自然临近(狄罗尼三角网临近)。 PS:当然,还有一种网格临近(cell2nb),这种一般在矢量数据里面很少存在,我就不说了。 2、spdep还支持利用距离函数来定义不同的权重,但是需要在定义了空间关系的情况下再使用。 3、如果对于默认的关系不满意,还可以自行定义空间关系。 4、空间关系可以不同类型的数据进行传递,如果有对应的唯一标识符,可以直接转换,如果没有,则需要但是需要自己写算法实现。直接转换的方法使用最简单排序即可。代码最后给出。 5、空间关系的选择没有一劳永逸的方法,需要根据研究的内容不断进行探索。
最后给出空间关系传统的方法:
首先两份数据,省会城市的点数据和省域面数据,其中,省会城市的点数据中有一列就是省域面数据的省级行政编码:
我们所要做的,就是同时对这两个空间数据框的这个一个列,进行排序即可,然后就可以进行自由传递了,如下所示:
代码实现如下
library("sp")
library("maptools")
library("spdep")
path <- "E:\\workspace\\IDE\\Rworkspace\\空间分析\\空间权重矩阵\\china\\"
#将中国的省级行政区划读取为ploygon,省会读取成point
cnData <- readShapePoly(paste(path,"CNPG_S.shp",sep =""))
ctData <- readShapePoints(paste(path,"city_SH.shp",sep =""))
cnData$FIRST_NAME <- iconv(cnData$FIRST_NAME,"UTF-8","GBK")
ctData$NAME <- iconv(ctData$NAME,"UTF-8","GBK")
#定义投影为wgs84
proj4string(cnData) <- "+proj=longlat +datum=WGS84"
proj4string(ctData) <- "+proj=longlat +datum=WGS84"
#同时利用同一字段排序即可实现传递
cnData <-cnData[order(cnData@data$Code),]
ctData <- ctData[order(ctData@data$S_CODE),]
ctIDs <- ctData$S_CODE
cnIDs <- cnData$Code
w_rn1 <- tri2nb(coordinates(ctData),row.names = ctIDs)
par(mfrow=c(2,1),mar=c(0,0,1,0))
plot(ctData,pch=19,cex=1,col='red')
text(ctData@coords[,1],ctData@coords[,2]+1,labels = ctData$NAME)
plot(nb2listw(w_rn1),coordinates(ctData),add=T)
title("省会点数据自然临近关系")
plot(cnData,border="grey")
plot(nb2listw(w_rn1),coordinates(cnData),add=T)
title("省会点数据自然临近关系传递")
文章来源:http://blog.csdn.net/allenlu2008/article/details/78166248

