
GeoEvent Server横向伸缩扩展(三)——安装和配置一个分布式事件调度中心(Apache Kafka)
分享
-
2017-09-18
前言
本文主要做了一件事,通过kafka横向扩展GeoEvent Server,构建GeoEvent+kafka集群部署。这件事有两个作用,其一,利用多台GeoEvent提高数据的吞吐量。其二,利用kafka集群的机制来提高GeoEvent Server软件的鲁棒性。
GeoEvent Server是用来实时接入的GIS数据的GIS实时服务器。而对于实时服务器来说,最重要的是系统的鲁棒性(Robustness)。什么是鲁棒性?鲁棒是Robust的音译,也就是健壮和强壮的意思。它是在异常和危险情况下系统生存的关键。比如说,计算机软件在输入错误、磁盘故障、网络过载或有意攻击情况下,能否不死机、不崩溃,就是该软件的鲁棒性。所谓“鲁棒性”,是指控制系统在一定(结构,大小)的参数摄动下,维持其它某些性能的特性。
自从Esri不推荐使用GeoEvent Server集群,而推荐采用GeoEvent Server单机部署后,GeoEvent Server的鲁棒性就成了用户关注的焦点。而现在,GeoEvent团队提供了一个方案,用来提高GeoEvent的鲁棒性以及横向扩展GeoEvent的能力。地址:http://www.arcgis.com/home/ite ... c8cc9。为了完成本教程,请您提前下载此链接中教程的附件。
此教程旨在发布5篇文章,来分别叙述以下五个章节。本文为第三节。安装和配置一个分布式事件调度中心(Apache Kafka)。
目录
1 GeoEvent弹性扩展架构
这一部分的目的是建立企业和ArcGIS的多个节点上,将在整个教程的其余部分使用ArcGIS GeoEvent Server。
2 熟悉事件中心概念(Apache Kafka)
本节中的练习将帮助您安装和探索事件调度中心的特性,包括使用多个broker进行冗余和伸缩。
3 安装和配置一个分布式事件调度中心(Apache Kafka)
本节基于前一节,将指导您在三个节点上安装和配置分布式事件调度中心。在本教程中,您将在3台已配置的GeoEvent Server节点上安装事件调度中心。
4 配置GeoEvent Server启用分布式事件调度中心
本节的目的是在一个分布式的事件调度中心完成GeoEvent Server配置。具体来说,你将学习如何使用Kafka 连接器配置GeoEvent Server接收消费从Apache Kafka生产的信息。 自定义连接器可在ArcGIS GeoEvent Gallery找到。
5 探讨GeoEvent Server利用分布式事件调度中心(Apache Kafka)实现鲁棒性
最后,在本节中,您将测试你的GeoEvent Server和kafka部署的鲁棒性,通过试验丢失brokers和丢失consumers,确保预期的消息仍然被接收并存储在系统中。
正文
3 安装和配置一个分布式事件调度中心(Apache Kafka)
在上一节中,您安装并探索了具有多个broker、分区话题和多个消费者的事件调度中心(Kafka),但都在单台计算机环境中。在本节中,您将配置一个分布式事件中心(Kafka)在ArcGIS GeoEvent Server三台机器上。
在下面的练习中,您将配置三个ZooKeeper实例和三个Kafka broker在三台不同的计算机上。在生产环境中,最好的做法是将这些资源与其他软件隔离,以获得最大的可靠性。为简单起见,在这个练习中,你将在之前配置的GeoEvent Server机器上建立分布式事件调度中心。
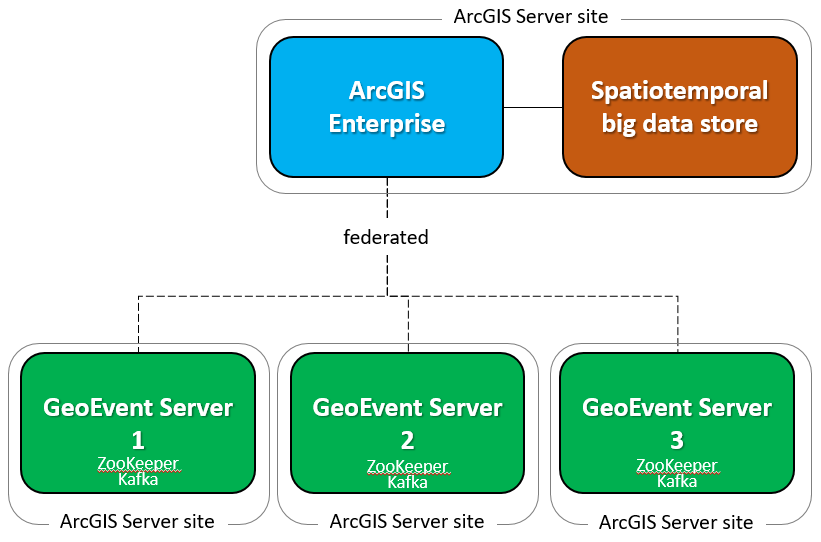
架构图
配置ZooKeeper实例
在Apache Kafka搭建的分布式事件中心,最好的方法是使用多个ZooKeeper实例实现可靠性。不同的ZooKeeper节点会协调选举一个主节点,并且当前主节点崩溃掉后,会选取一个新的主节点。
在每个GeoEvent Server机器重复以下步骤(machine3,machine4 和 machine5)为分布式事件调度中心运行ZooKeeper。
首先你需要像上一章“<a href="http://www.jianshu.com/p/a4027 ... Event Server横向伸缩扩展(二)——熟悉事件中心概念”里的做法,给每台GE机器安装jdk,解压提取Apache Kafka下载包。
1.复制一个文件副本%KAFKA_HOME%\config\zookeeper.properties文件命名为zookeeper-replicated.properties.
2.编辑Zookeeper-replicated.properties文件,指定你将使用的端口。
注意:如果以这个练习为例,你在GeoEvent Server节点上运行Zookeeper,确保你使用的端口与ArcGIS Zookeeper平台服务运行的端口不冲突。

Zookeeper-replicated.properties
3.取决于windows系统,你可能需要更改log文件的路径。例如:
dataDir=C:\\tmp\\zookeeper
4.添加下面几行到zookeeper-replicated.properties文件:
initLimit=5
syncLimit=2
initLimit参数设定了允许所有跟随者与领导者进行连接并同步的时间,如果在设定的时间段内,半数以上的跟随者未能完成同步,领导者便会宣布放弃领导地位,进行另一次的领导选举。如果zk集群环境数量确实很大,同步数据的时间会变长,因此这种情况下可以适当调大该参数。默认为10
syncLimit参数设定了允许一个跟随者与一个领导者进行同步的时间,如果在设定的时间段内,跟随者未完成同步,它将会被集群丢弃。所有关联到这个跟随者的客户端将连接到另外一个跟随者。
5.向zookeeper-replicated.properties文件中添加下面几行,每行用每台GeoEvent 机器的全域名限定格式的主机名替换掉zoo1/zoo2/zoo3.
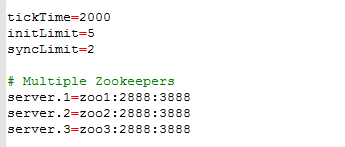
集群配置
例如:
server.1=machine3.domain.com:2888:3888
server.2=machine4.domain.com:2888:3888
server.3=machine5.domain.com:2888:3888
第一个端口(2888)是Zookeeper节点之间相互连接和协定更新顺序所使用的。第二个端口(3888)是用于选举的端口,更多信息请参考ApacheZookeeper文档
6.保存并关闭文件。拷贝这个文件到另外两个GeoEvent Server节点机器上可以节省重复以上操作的时间。
完成了以上步骤后,你的每一个GeoEvent Server节点都成为了ZooKeeper的一员。当Zookeeper开始运行时,它需要知道它代表的是哪个节点。你将要创建id文件来告诉ZooKeeper它的节点(服务器)的id。
7.访问C:\tmp\zookeeper,如果不存在请创建。
8.创建一个新文件叫做myid,不带任何扩展名。
注意一个新文件myid.txt然后重命名移除扩展名。
9.使用文本编辑器编辑文件输入你指定此节点replicated.properties文件的id
例如,如果在这台GeoEvent Server节点你定为Server1,你的myid文件中就应该是如下内容。
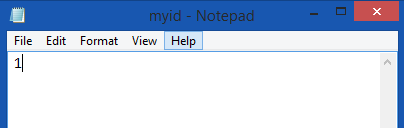
myid1
10.保存并关闭myid文件
11.确定文件存在C:\tmp\zookeeper\myid(没有文件后缀名)。
12.用下面的命令启动ZooKeeper:
bin\windows\zookeeper-server-start.bat config\zookeeper-replicated.properties
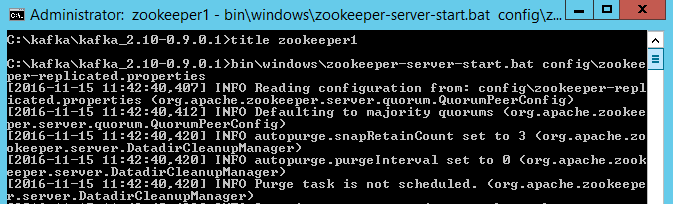
分布式启动ZooKeeper
13.当你在每个GeoEvent Server机器上使用ZooKeeper-replicated.properties配置文件启动ZooKeeper时,关于leader选取的消息会出现。

leader竞选
14.在每台GeoEvent机器上,保持ZooKeeper命令行开启,进程正在运行。方便后面的练习使用。
配置Kafka broker
使用你前面的练习中已有的知识在每台GeoEvent Server机器上启动Kafka broker。
1.在%KAFKA_HOME%\config 目录,编辑server properties 文件(或者创建一个新的)反映Kafka broker在机器上的配置属性。
a.设置broker.id为0,1和2,取决于在哪个GeoEvent Server节点上。
b.设置listeners端口,在每个机器上可以是一样的端口。
c.为你的日志设置路径
可选项:取决于你的windows版本,你需要修改路径格式。
dataDir=c:\\tmp\\kafka-log-0
d.设置ZooKeeper端口,可以是2183,和之前一样。
e.添加一个属性,开启话题可删除功能。
2.从命令行运行Kafka,使用上一步你刚刚编辑的配置文件:

运行Kafka broker
注意:如果你看到错误在ZooKeeper,你可能需要首先停止并重启ZooKeeper进程。
3.保持Kafka broker进程运行,方便后面的练习。
配置Kafka订阅者和生产者
1.使用前面练习中已有知识创建新话题具有3个分片和3个副本。你可以给话题任意名称。
bin\windows\kafka-topics.bat --create --zookeeper localhost:2183 --replication-factor 3 --partitions 3 --topic trains

trains话题详情
2.使用前面练习中获得的创建三个trains话题下的订阅者/消费者,每台GeoEvent Server 机器上有一个。
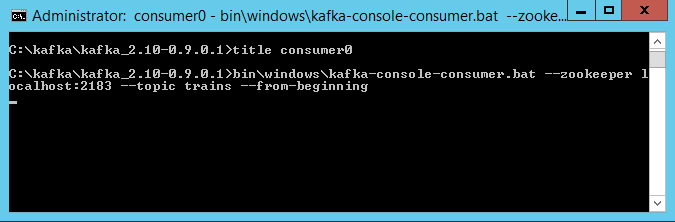
创建消费者
3.当你有了三个消费者,可以创建生产者在话题上生产消息并开始发送消息。
例如:
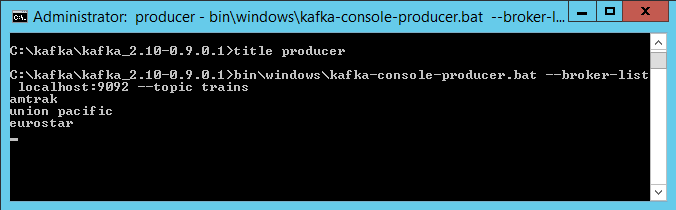
创建消息并发送消息

消费者接收消息
如果你配置的消费者没有一个共有的消费者group id ,你将看到相同的消息流向三个消费者(在不同的机器上)。
如果使用共有的消费者群组,就会看到消息被分发到每一个消费者上,不出现重复。
4.可选项:如果需要,你还可以测试分布式部署中的高可用性。
a.不停止你的生产者和消费者,在一台GeoEvent Server机器上,停止Kafka 进程。
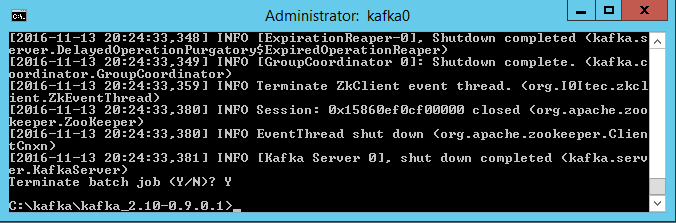
停止一个Kafka节点
b.回到你的生产者命令窗口,继续发送消息。

继续发送两条消息
在所有的三个消费者上,你的消费者会显示丢失broker的消息,但会继续接收所有的消息。

消费者继续接收消息
c.你可以继续测试停止掉消费者中的一个,然后观察剩下的两个消费者继续接收所有事件。
5.清空。
a.在每一个GeoEvent Server节点,停止消费者进程,关闭他们的命令行窗口。
b.结束生产者进程,删除上一个练习中创建的分布式话题并关闭他们的命令行窗口。
c.如果你执行了高可用性测试的可选项,你现在有一个已停止的Kafka broker——重启这个Kafka broker 使用相同的配置文件。
d.保持所有的ZooKeeper实例和Kafka broker都在运行状态,为后面的练习做准备。
在这一节中,你成功的使用Apache Kafka配置了一个分布式事件调度中心。在下一节中,你将配置每一个GeoEvent节点从Kafka话题中接收事件。
本篇教程配置了一个分布式事件调度中心,可以看出Apache Kafka在做分布式扩展时是非常容易配置的。和前一篇的区别就是跨机器运行。在下一篇文章中,我们将会使用GeoEvent和Kafka结合,充分利用分布式事件调度的机制,事件将会被分发到各个GeoEvent Server中,确保每个GeoEvent接收的事件不重复,并通过分发事件,实现GeoEvent横向扩展,提高吞吐量和鲁棒性。请期待下一篇文章......
GeoEvent Server横向伸缩扩展(一)——ArcGIS GeoEvent弹性架构:http://zhihu.esrichina.com.cn/article/3333
GeoEvent Server横向伸缩扩展(二)——熟悉事件中心概念:http://zhihu.esrichina.com.cn/article/3338
GeoEvent Server横向伸缩扩展(三)——安装和配置一个分布式事件调度中心(Apache Kafka):http://zhihu.esrichina.com.cn/article/3431
文章来源:http://www.jianshu.com/p/e24f30ad058f
本文主要做了一件事,通过kafka横向扩展GeoEvent Server,构建GeoEvent+kafka集群部署。这件事有两个作用,其一,利用多台GeoEvent提高数据的吞吐量。其二,利用kafka集群的机制来提高GeoEvent Server软件的鲁棒性。
GeoEvent Server是用来实时接入的GIS数据的GIS实时服务器。而对于实时服务器来说,最重要的是系统的鲁棒性(Robustness)。什么是鲁棒性?鲁棒是Robust的音译,也就是健壮和强壮的意思。它是在异常和危险情况下系统生存的关键。比如说,计算机软件在输入错误、磁盘故障、网络过载或有意攻击情况下,能否不死机、不崩溃,就是该软件的鲁棒性。所谓“鲁棒性”,是指控制系统在一定(结构,大小)的参数摄动下,维持其它某些性能的特性。
自从Esri不推荐使用GeoEvent Server集群,而推荐采用GeoEvent Server单机部署后,GeoEvent Server的鲁棒性就成了用户关注的焦点。而现在,GeoEvent团队提供了一个方案,用来提高GeoEvent的鲁棒性以及横向扩展GeoEvent的能力。地址:http://www.arcgis.com/home/ite ... c8cc9。为了完成本教程,请您提前下载此链接中教程的附件。
此教程旨在发布5篇文章,来分别叙述以下五个章节。本文为第三节。安装和配置一个分布式事件调度中心(Apache Kafka)。
目录
1 GeoEvent弹性扩展架构
这一部分的目的是建立企业和ArcGIS的多个节点上,将在整个教程的其余部分使用ArcGIS GeoEvent Server。
2 熟悉事件中心概念(Apache Kafka)
本节中的练习将帮助您安装和探索事件调度中心的特性,包括使用多个broker进行冗余和伸缩。
3 安装和配置一个分布式事件调度中心(Apache Kafka)
本节基于前一节,将指导您在三个节点上安装和配置分布式事件调度中心。在本教程中,您将在3台已配置的GeoEvent Server节点上安装事件调度中心。
4 配置GeoEvent Server启用分布式事件调度中心
本节的目的是在一个分布式的事件调度中心完成GeoEvent Server配置。具体来说,你将学习如何使用Kafka 连接器配置GeoEvent Server接收消费从Apache Kafka生产的信息。 自定义连接器可在ArcGIS GeoEvent Gallery找到。
5 探讨GeoEvent Server利用分布式事件调度中心(Apache Kafka)实现鲁棒性
最后,在本节中,您将测试你的GeoEvent Server和kafka部署的鲁棒性,通过试验丢失brokers和丢失consumers,确保预期的消息仍然被接收并存储在系统中。
正文
3 安装和配置一个分布式事件调度中心(Apache Kafka)
在上一节中,您安装并探索了具有多个broker、分区话题和多个消费者的事件调度中心(Kafka),但都在单台计算机环境中。在本节中,您将配置一个分布式事件中心(Kafka)在ArcGIS GeoEvent Server三台机器上。
在下面的练习中,您将配置三个ZooKeeper实例和三个Kafka broker在三台不同的计算机上。在生产环境中,最好的做法是将这些资源与其他软件隔离,以获得最大的可靠性。为简单起见,在这个练习中,你将在之前配置的GeoEvent Server机器上建立分布式事件调度中心。
架构图
配置ZooKeeper实例
在Apache Kafka搭建的分布式事件中心,最好的方法是使用多个ZooKeeper实例实现可靠性。不同的ZooKeeper节点会协调选举一个主节点,并且当前主节点崩溃掉后,会选取一个新的主节点。
在每个GeoEvent Server机器重复以下步骤(machine3,machine4 和 machine5)为分布式事件调度中心运行ZooKeeper。
首先你需要像上一章“<a href="http://www.jianshu.com/p/a4027 ... Event Server横向伸缩扩展(二)——熟悉事件中心概念”里的做法,给每台GE机器安装jdk,解压提取Apache Kafka下载包。
1.复制一个文件副本%KAFKA_HOME%\config\zookeeper.properties文件命名为zookeeper-replicated.properties.
2.编辑Zookeeper-replicated.properties文件,指定你将使用的端口。
注意:如果以这个练习为例,你在GeoEvent Server节点上运行Zookeeper,确保你使用的端口与ArcGIS Zookeeper平台服务运行的端口不冲突。
Zookeeper-replicated.properties
3.取决于windows系统,你可能需要更改log文件的路径。例如:
dataDir=C:\\tmp\\zookeeper
4.添加下面几行到zookeeper-replicated.properties文件:
initLimit=5
syncLimit=2
initLimit参数设定了允许所有跟随者与领导者进行连接并同步的时间,如果在设定的时间段内,半数以上的跟随者未能完成同步,领导者便会宣布放弃领导地位,进行另一次的领导选举。如果zk集群环境数量确实很大,同步数据的时间会变长,因此这种情况下可以适当调大该参数。默认为10
syncLimit参数设定了允许一个跟随者与一个领导者进行同步的时间,如果在设定的时间段内,跟随者未完成同步,它将会被集群丢弃。所有关联到这个跟随者的客户端将连接到另外一个跟随者。
5.向zookeeper-replicated.properties文件中添加下面几行,每行用每台GeoEvent 机器的全域名限定格式的主机名替换掉zoo1/zoo2/zoo3.
集群配置
例如:
server.1=machine3.domain.com:2888:3888
server.2=machine4.domain.com:2888:3888
server.3=machine5.domain.com:2888:3888
第一个端口(2888)是Zookeeper节点之间相互连接和协定更新顺序所使用的。第二个端口(3888)是用于选举的端口,更多信息请参考ApacheZookeeper文档
6.保存并关闭文件。拷贝这个文件到另外两个GeoEvent Server节点机器上可以节省重复以上操作的时间。
完成了以上步骤后,你的每一个GeoEvent Server节点都成为了ZooKeeper的一员。当Zookeeper开始运行时,它需要知道它代表的是哪个节点。你将要创建id文件来告诉ZooKeeper它的节点(服务器)的id。
7.访问C:\tmp\zookeeper,如果不存在请创建。
8.创建一个新文件叫做myid,不带任何扩展名。
注意一个新文件myid.txt然后重命名移除扩展名。
9.使用文本编辑器编辑文件输入你指定此节点replicated.properties文件的id
例如,如果在这台GeoEvent Server节点你定为Server1,你的myid文件中就应该是如下内容。
myid1
10.保存并关闭myid文件
11.确定文件存在C:\tmp\zookeeper\myid(没有文件后缀名)。
12.用下面的命令启动ZooKeeper:
bin\windows\zookeeper-server-start.bat config\zookeeper-replicated.properties
分布式启动ZooKeeper
13.当你在每个GeoEvent Server机器上使用ZooKeeper-replicated.properties配置文件启动ZooKeeper时,关于leader选取的消息会出现。
leader竞选
14.在每台GeoEvent机器上,保持ZooKeeper命令行开启,进程正在运行。方便后面的练习使用。
配置Kafka broker
使用你前面的练习中已有的知识在每台GeoEvent Server机器上启动Kafka broker。
1.在%KAFKA_HOME%\config 目录,编辑server properties 文件(或者创建一个新的)反映Kafka broker在机器上的配置属性。
a.设置broker.id为0,1和2,取决于在哪个GeoEvent Server节点上。
b.设置listeners端口,在每个机器上可以是一样的端口。
c.为你的日志设置路径
可选项:取决于你的windows版本,你需要修改路径格式。
dataDir=c:\\tmp\\kafka-log-0
d.设置ZooKeeper端口,可以是2183,和之前一样。
e.添加一个属性,开启话题可删除功能。
2.从命令行运行Kafka,使用上一步你刚刚编辑的配置文件:
运行Kafka broker
注意:如果你看到错误在ZooKeeper,你可能需要首先停止并重启ZooKeeper进程。
3.保持Kafka broker进程运行,方便后面的练习。
配置Kafka订阅者和生产者
1.使用前面练习中已有知识创建新话题具有3个分片和3个副本。你可以给话题任意名称。
bin\windows\kafka-topics.bat --create --zookeeper localhost:2183 --replication-factor 3 --partitions 3 --topic trains
trains话题详情
2.使用前面练习中获得的创建三个trains话题下的订阅者/消费者,每台GeoEvent Server 机器上有一个。
创建消费者
3.当你有了三个消费者,可以创建生产者在话题上生产消息并开始发送消息。
例如:
创建消息并发送消息
消费者接收消息
如果你配置的消费者没有一个共有的消费者group id ,你将看到相同的消息流向三个消费者(在不同的机器上)。
如果使用共有的消费者群组,就会看到消息被分发到每一个消费者上,不出现重复。
4.可选项:如果需要,你还可以测试分布式部署中的高可用性。
a.不停止你的生产者和消费者,在一台GeoEvent Server机器上,停止Kafka 进程。
停止一个Kafka节点
b.回到你的生产者命令窗口,继续发送消息。
继续发送两条消息
在所有的三个消费者上,你的消费者会显示丢失broker的消息,但会继续接收所有的消息。
消费者继续接收消息
c.你可以继续测试停止掉消费者中的一个,然后观察剩下的两个消费者继续接收所有事件。
5.清空。
a.在每一个GeoEvent Server节点,停止消费者进程,关闭他们的命令行窗口。
b.结束生产者进程,删除上一个练习中创建的分布式话题并关闭他们的命令行窗口。
c.如果你执行了高可用性测试的可选项,你现在有一个已停止的Kafka broker——重启这个Kafka broker 使用相同的配置文件。
d.保持所有的ZooKeeper实例和Kafka broker都在运行状态,为后面的练习做准备。
在这一节中,你成功的使用Apache Kafka配置了一个分布式事件调度中心。在下一节中,你将配置每一个GeoEvent节点从Kafka话题中接收事件。
本篇教程配置了一个分布式事件调度中心,可以看出Apache Kafka在做分布式扩展时是非常容易配置的。和前一篇的区别就是跨机器运行。在下一篇文章中,我们将会使用GeoEvent和Kafka结合,充分利用分布式事件调度的机制,事件将会被分发到各个GeoEvent Server中,确保每个GeoEvent接收的事件不重复,并通过分发事件,实现GeoEvent横向扩展,提高吞吐量和鲁棒性。请期待下一篇文章......
GeoEvent Server横向伸缩扩展(一)——ArcGIS GeoEvent弹性架构:http://zhihu.esrichina.com.cn/article/3333
GeoEvent Server横向伸缩扩展(二)——熟悉事件中心概念:http://zhihu.esrichina.com.cn/article/3338
GeoEvent Server横向伸缩扩展(三)——安装和配置一个分布式事件调度中心(Apache Kafka):http://zhihu.esrichina.com.cn/article/3431
文章来源:http://www.jianshu.com/p/e24f30ad058f
