
大数据架构思考(三)
分享
-
2017-09-11
越十年生聚,而十年教训,二十年之外,吴其为沼乎。——《左传 ·哀公元年》
越人为了报仇,准备了二十年,其中10年用来生育,十年用来教育训练,——怀胎十月,成长十年,教育十年方能成为一个合格的战士。

OK,突然有一天,一个叫做大数据神突然来造访越王勾践来了……神告诉我们,大数据可以并行计算……也就是把很多机器合并起来,提高性能和速度。
那么:

以上场景,是不是特别像现在很多大数据的需求场景?
你们不是说并行计算,可以加快么?我的数据量就这么多,1台机器十分钟,那给你10台机器,你一分钟给我算出来……
嗯……北京到上海,一趟高铁需要5个小时,现在我给你5趟高铁,麻烦你在1小时之内把我从北京送到上海,谢谢啊,亲爱的达瓦里希.大(товарищ,毛子语“同”志的意思)。
虽然说,理论上并行计算的原理如下:
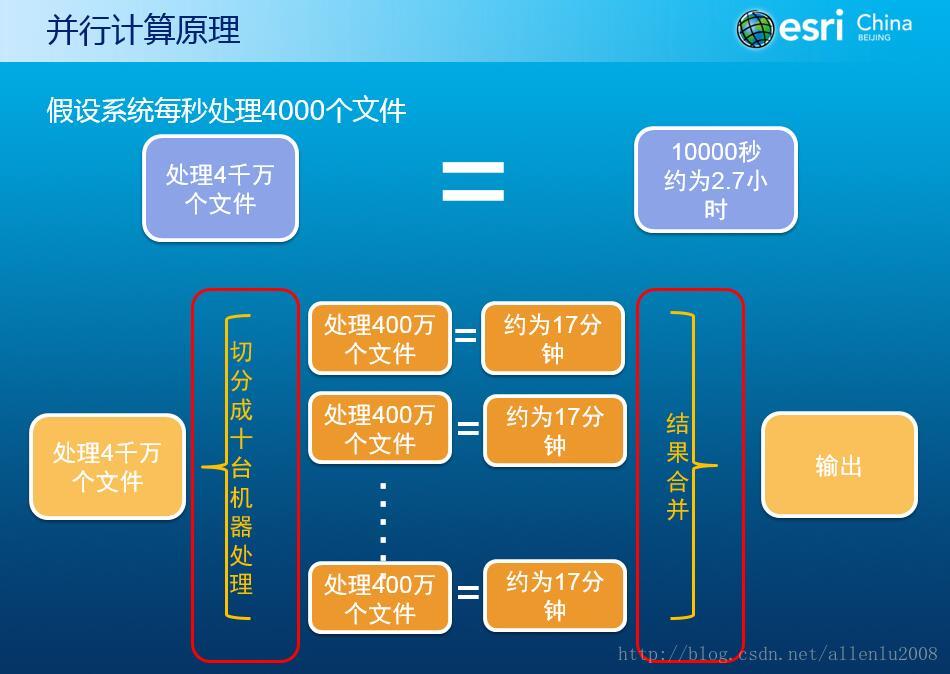
但是实际上,有如下几个关键点需要明确:
第一:切分任务和结果合并的开销。
这个两个步骤是属于串行的,所以无论如何是硬性的时间开销。
因为集群之间的通信,都是利用网络进行的,那么我们可以自己在脑子里面脑补一下把一份数据从存储节点发送到运算节点需要的时间:
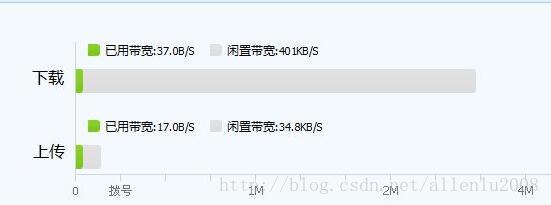
而对于大数据(量)来说,动辄TB,设置PB,那小小的网络小水管,需要多少时间才能给把需要计算的数据和计算的模型匹配起来?
但是hadoop/spark这样的框架,给了一个比较好的解决方法,把计算模型,发送到数据节点上去,这样可以有效的减少集群之间的网络开销,但是减少不代表没有,只要有传输,就要有时间开销。
第二,在Hadoop和Spark框架中,任务切分的粒度也是有规则的。
原始情况下,hadoop的默认任务分片大小是64M,后来扩大为128M。表示你要分析的任务,将被切分为最小128M一个的任务块,分析这一个任务块的时间,就是最小的时间片段。
不说,给你1000台机器,就能把数据分配到这1000台机器上运算的。
所以,并行计算或者说大数据并行计算,解决的是庞大数据计算效率的问题,而非简单的速度问题。
回到前面给出的高铁假设:
一趟高铁,5小时能从北京跑到上海,那么给五趟高铁,肯定也没办法在一小时之内做到。但是如果是1趟高铁只能运载500人,那么5趟高铁可以在同样的时间内,把2500人,从北京运送到上海去。
传统企业,最大的痛点是庞大的数据,无法快速分析,但是传统企业的特点也是这庞大的数据几乎是静态的,今天是100GB,明天还是100GB,起码在一个时间段内,不会以几何级数的增长。
所以传统企业的脑海里面,就出现了1台机器2小时分析完成,给你1000台机器,那么7秒你就给算完这种思想——数据量不变的情况下,增加机器,就能加快速度,这就是传统企业里面很多用户对“性能”这个词的理解。
实际上这种理解,差不多就等于给5趟高铁,就能1小时把人从北京送到上海是一样。
大数据思想下的“性能”,实际上给出的第二种思想:1台机器处理100G数据,要2小时,那么你的数据正在到1000GB的时候,给我10台机器,也能在2小时处理完成。就等于5趟高铁,可以在同样的时间内完成2500人的运输任务。
回归最原始的阿里巴巴对hadoop框架的应用场景:
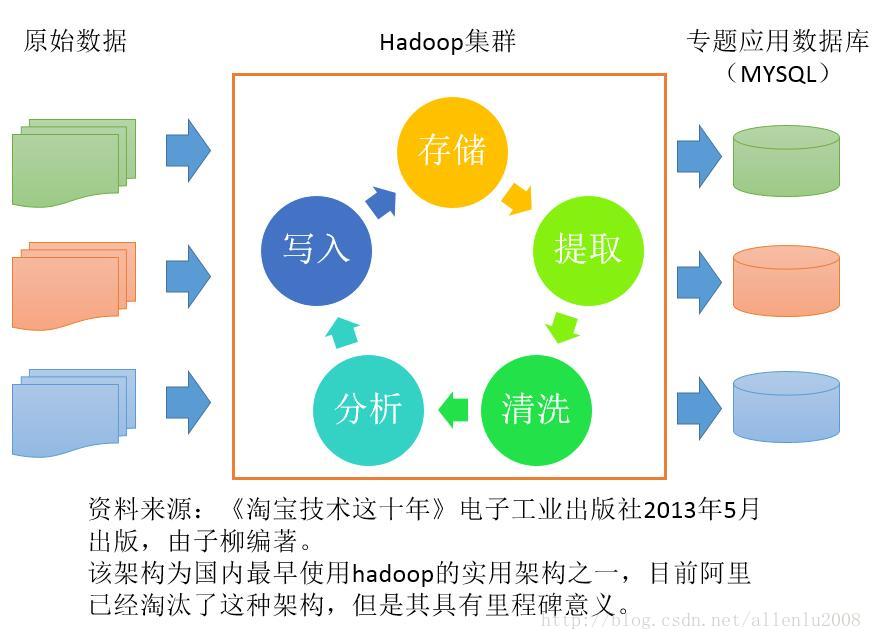
如果hadoop/spark真的为了(传统意义上的)速度存在的,那么为什么阿里最后还是要将数据写入到mysql里面呢?因为hadoop/spark他们的存在,并不是用来和传统数据库比实时响应效率的。
那这样说来,大数据的并行计算还有价值么?能不能够提升我的计算效率呢?
答案是肯定的。
回到前面那个假设,1小时之内,利用高铁,把货物送到上海。怎么做?答案是利用中转仓储。在北京到上海之间设立5个中转站,然后把货物存放在中转站里面,每个高铁只需要在这1小时区间内运行,那么只要建立好了中转站(预先开销),那么之后就可以在一小时内收到货物了。也就是流水线作业。
这里带来的问题就变成了哪些货物放到哪些中转站里面?如果这个中转站里面没有我需要,而在其他中转站里面怎么办?这就是spark提出的一个调度算法,决定你哪些数据需要重复使用(中转站内存储的货物的选择),然后利用调度算法,来减少这种“我需要,但是最近的一个中转站木有”的问题。
那么回归到数据分析中,如何来利用这种思想呢?
答案就是中间数据。
将原始数据按照需要,组织成中间数据,然后前端的分析,实际上调用的是这些中间的数据。
比如要在1秒之内,计算整个京九沿线九个省一共有多少耕地?
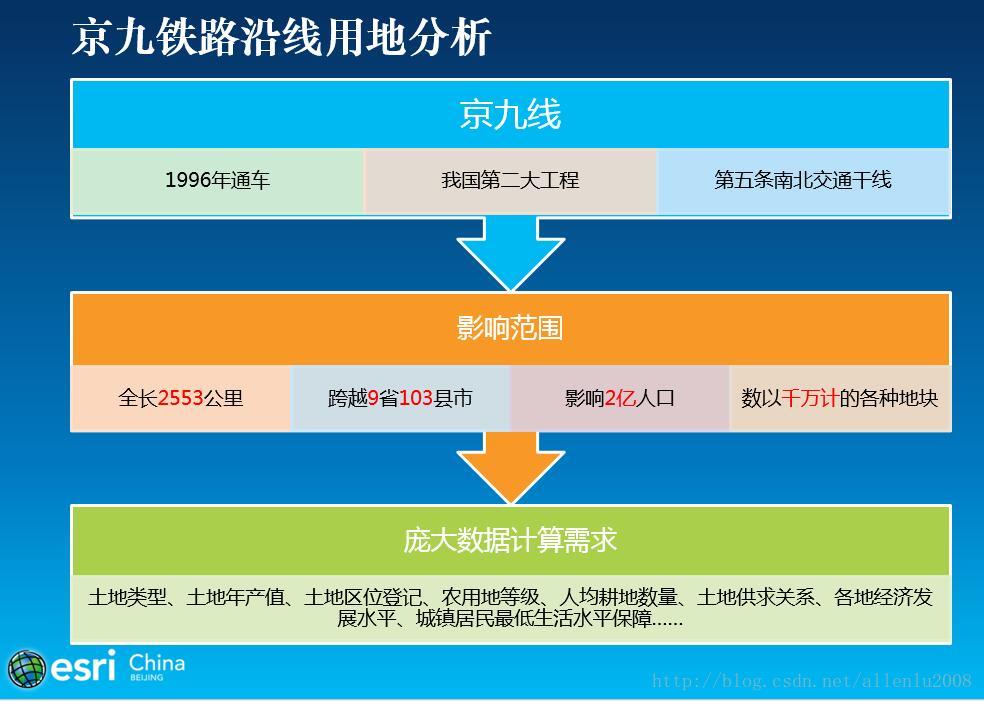
如果从原始数据里面去计算,起码超过100个小时(国土的数据是分库存储的,一个县一个库,103个县,就要跨越103库去进行查询。
但是利用大数据的模式么?
先把所有的地块,聚合计算到10平方公里的网格里面,那么这个中间数据,全国也就90多万个网格。每个网格里面记录了每种地块类型的count、sum等统计聚合值。
现在只需要利用京九线对90多万个网格做个相交计算即可。
那么得到的数据,可能不是完全正确的,因为每个网格里面仅有统计值。那么最后的的出来的数据,到底是1亿3千623万1456.4447亩,还得出1亿3千600多万亩,在这种数据量的统计下,有多少大的差别?
根据目前最新的试验,使用1平方公里网格,对千万级地块覆盖面积超过10万平方公里的区域的数据进行聚合,原始数据和网格数据查询出来的结果,误差率仅为百分之0.7,也就是说精确度高达99.3%。
在百分之0.7的误差度与100小时和10秒钟之间,获取一个平衡点,如何去取舍,才是大数据分析手段和传统分析思路的一个碰撞。
大数据项目架构思考(一):http://zhihu.esrichina.com.cn/article/3336
大数据项目架构思考(二):http://zhihu.esrichina.com.cn/article/3335
大数据项目架构思考(三):http://zhihu.esrichina.com.cn/article/3341
文章来源:http://blog.csdn.net/allenlu2008/article/details/77880682
越人为了报仇,准备了二十年,其中10年用来生育,十年用来教育训练,——怀胎十月,成长十年,教育十年方能成为一个合格的战士。
OK,突然有一天,一个叫做大数据神突然来造访越王勾践来了……神告诉我们,大数据可以并行计算……也就是把很多机器合并起来,提高性能和速度。
那么:
以上场景,是不是特别像现在很多大数据的需求场景?
你们不是说并行计算,可以加快么?我的数据量就这么多,1台机器十分钟,那给你10台机器,你一分钟给我算出来……
嗯……北京到上海,一趟高铁需要5个小时,现在我给你5趟高铁,麻烦你在1小时之内把我从北京送到上海,谢谢啊,亲爱的达瓦里希.大(товарищ,毛子语“同”志的意思)。
虽然说,理论上并行计算的原理如下:
但是实际上,有如下几个关键点需要明确:
第一:切分任务和结果合并的开销。
这个两个步骤是属于串行的,所以无论如何是硬性的时间开销。
因为集群之间的通信,都是利用网络进行的,那么我们可以自己在脑子里面脑补一下把一份数据从存储节点发送到运算节点需要的时间:
而对于大数据(量)来说,动辄TB,设置PB,那小小的网络小水管,需要多少时间才能给把需要计算的数据和计算的模型匹配起来?
但是hadoop/spark这样的框架,给了一个比较好的解决方法,把计算模型,发送到数据节点上去,这样可以有效的减少集群之间的网络开销,但是减少不代表没有,只要有传输,就要有时间开销。
第二,在Hadoop和Spark框架中,任务切分的粒度也是有规则的。
原始情况下,hadoop的默认任务分片大小是64M,后来扩大为128M。表示你要分析的任务,将被切分为最小128M一个的任务块,分析这一个任务块的时间,就是最小的时间片段。
不说,给你1000台机器,就能把数据分配到这1000台机器上运算的。
所以,并行计算或者说大数据并行计算,解决的是庞大数据计算效率的问题,而非简单的速度问题。
回到前面给出的高铁假设:
一趟高铁,5小时能从北京跑到上海,那么给五趟高铁,肯定也没办法在一小时之内做到。但是如果是1趟高铁只能运载500人,那么5趟高铁可以在同样的时间内,把2500人,从北京运送到上海去。
传统企业,最大的痛点是庞大的数据,无法快速分析,但是传统企业的特点也是这庞大的数据几乎是静态的,今天是100GB,明天还是100GB,起码在一个时间段内,不会以几何级数的增长。
所以传统企业的脑海里面,就出现了1台机器2小时分析完成,给你1000台机器,那么7秒你就给算完这种思想——数据量不变的情况下,增加机器,就能加快速度,这就是传统企业里面很多用户对“性能”这个词的理解。
实际上这种理解,差不多就等于给5趟高铁,就能1小时把人从北京送到上海是一样。
大数据思想下的“性能”,实际上给出的第二种思想:1台机器处理100G数据,要2小时,那么你的数据正在到1000GB的时候,给我10台机器,也能在2小时处理完成。就等于5趟高铁,可以在同样的时间内完成2500人的运输任务。
回归最原始的阿里巴巴对hadoop框架的应用场景:
如果hadoop/spark真的为了(传统意义上的)速度存在的,那么为什么阿里最后还是要将数据写入到mysql里面呢?因为hadoop/spark他们的存在,并不是用来和传统数据库比实时响应效率的。
那这样说来,大数据的并行计算还有价值么?能不能够提升我的计算效率呢?
答案是肯定的。
回到前面那个假设,1小时之内,利用高铁,把货物送到上海。怎么做?答案是利用中转仓储。在北京到上海之间设立5个中转站,然后把货物存放在中转站里面,每个高铁只需要在这1小时区间内运行,那么只要建立好了中转站(预先开销),那么之后就可以在一小时内收到货物了。也就是流水线作业。
这里带来的问题就变成了哪些货物放到哪些中转站里面?如果这个中转站里面没有我需要,而在其他中转站里面怎么办?这就是spark提出的一个调度算法,决定你哪些数据需要重复使用(中转站内存储的货物的选择),然后利用调度算法,来减少这种“我需要,但是最近的一个中转站木有”的问题。
那么回归到数据分析中,如何来利用这种思想呢?
答案就是中间数据。
将原始数据按照需要,组织成中间数据,然后前端的分析,实际上调用的是这些中间的数据。
比如要在1秒之内,计算整个京九沿线九个省一共有多少耕地?
如果从原始数据里面去计算,起码超过100个小时(国土的数据是分库存储的,一个县一个库,103个县,就要跨越103库去进行查询。
但是利用大数据的模式么?
先把所有的地块,聚合计算到10平方公里的网格里面,那么这个中间数据,全国也就90多万个网格。每个网格里面记录了每种地块类型的count、sum等统计聚合值。
现在只需要利用京九线对90多万个网格做个相交计算即可。
那么得到的数据,可能不是完全正确的,因为每个网格里面仅有统计值。那么最后的的出来的数据,到底是1亿3千623万1456.4447亩,还得出1亿3千600多万亩,在这种数据量的统计下,有多少大的差别?
根据目前最新的试验,使用1平方公里网格,对千万级地块覆盖面积超过10万平方公里的区域的数据进行聚合,原始数据和网格数据查询出来的结果,误差率仅为百分之0.7,也就是说精确度高达99.3%。
在百分之0.7的误差度与100小时和10秒钟之间,获取一个平衡点,如何去取舍,才是大数据分析手段和传统分析思路的一个碰撞。
大数据项目架构思考(一):http://zhihu.esrichina.com.cn/article/3336
大数据项目架构思考(二):http://zhihu.esrichina.com.cn/article/3335
大数据项目架构思考(三):http://zhihu.esrichina.com.cn/article/3341
文章来源:http://blog.csdn.net/allenlu2008/article/details/77880682

