
大数据项目架构思考(二)
分享
-
2017-09-06
大数据架构思考(二)

世界上第一架(也是唯一?的)不锈钢制造的战斗机:国内军迷亲切的称呼它为“青翼蝠王”……从分量上来看,比西方那些用各种合金材料打造的妖艳货压秤多了,但是就这么个超级“秤砣”,不但飞起来了,还创造了当年在速度上面的N多项世界纪录。
所以,毛熊大哥们告诉我们的语录,我们一直记在心头:

进入21世纪的第二个10年,一种名叫“大数据”的技术,突然开始流行起来了,首先是在互联网,然后慢慢的流窜到了传统领域,于是乎,各种以“大数据”为名的宗教开始大行其道:
人们呐……你们罪孽深重呐(重得跟你们的钱包似的)……快使用大数据,哼哼哈嘿……信大数据者得永生……

所以在实际的工作中,有大量的用传统技术无法解决的痛点,都把希望寄托在了大数据技术上面。
比如:上亿级别的地块图斑,希望能够在很短(最好几秒……当年能到毫秒就更好了)的时间内完成各种复杂查询和统计。
什么?你说数据库为什么不行?这是有很多客观原因的。
现在我觉得数据库不行了,那么你不是大数据来了么?这样吧,上大数据(不管你们用Hadoop还是用Spark,先帮我把这个事情给我解决掉。)
如果说,大数据技术类似于制造了一个压路机,提供给需要修路的单位使用,而突然被玩赛车的公司看中了,想用这个压路机来跑F1方程式——理由是:你这个压路机的马力这么大,跑起来肯定很快……
如果我们千方百计告诉客户,压路机马力这么大,但是他的速度不一定会快——比如,他在赛道上,肯定没有F1赛车快。客户勉为其难就算接受了这个的忠告。
但是,毛熊大哥的话记心头……他们会这样问我们:你们的压路机马力这大,发动机肯定很强悍吧?来来来,把你们压路机的发动机拆下来,安装到F1赛车上,那么我们的F1赛车是不是就可以跑得很快了。
客户错了吗?当然没错,他们的理解,就停留在马力大,就速度快的基础上。至于什么架构、技术背景、适用场景、体量重量等等等,都不在他们的考虑范围内。
遇上这种情况,我特别想在心里面问候一句:what the fuck……
但是作为有素质有理想的五好青年,虾神是不能问候WTF,所以就要想办法让压路机在平时主要干修路工作的时候,还要挖掘潜能,跑出F1赛车的速度来。
要了解大数据分析工具到底能做什么?首先要了解大数据分析的一些基本概念。
大数据技术并不是为了专门解决传统模式痛点而产生的,目前解决传统模式只是大数据技术发展中的一个附带的产物。
就像研制压路机的发动机,不是为了让这个发动机可以给F1赛车提速上一样。
大数据这几年被严重的神话了,变成了宗教崇拜。实施大数据项目,应该是有充分且严格的前提条件的,我们近些年遇见的,基本上是以大数据为名,做传统的数据中心和数据分析。因为遇见的数据,除了量以外,都不是大数据意义上的内容。
而大数据意义上的数据,就以LBS数据(比如车辆的GPS)而论,除去大家都有数据量巨大这点以外,有这样一些特点:
1、单条价值密度极低(单条价值密度无限接近与0),任何一个点的GPS数据,都没有任何独立的意义,需要有大量的数据聚集在一起,形成数据链,或者数据块,才会有意义。
比如下面的情况:任何一个点,单独提出来,有啥意义么?
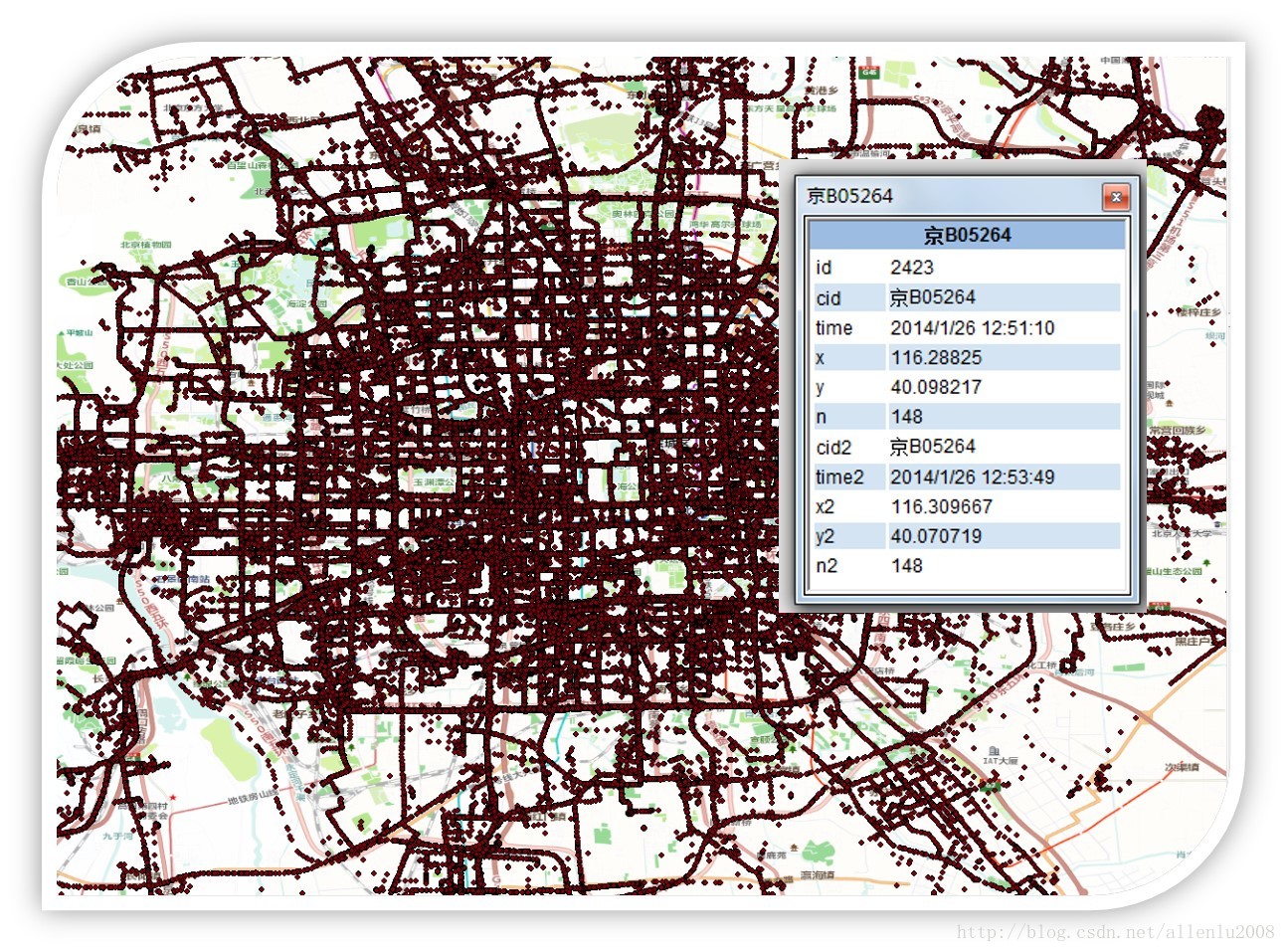
但是,形成数据块或者数据链之后,进行整体的趋势了解:
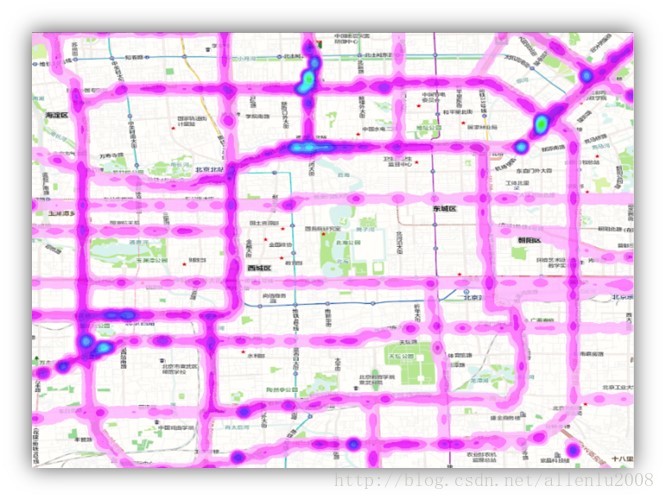
或者是大量数据的统计性质的信息:
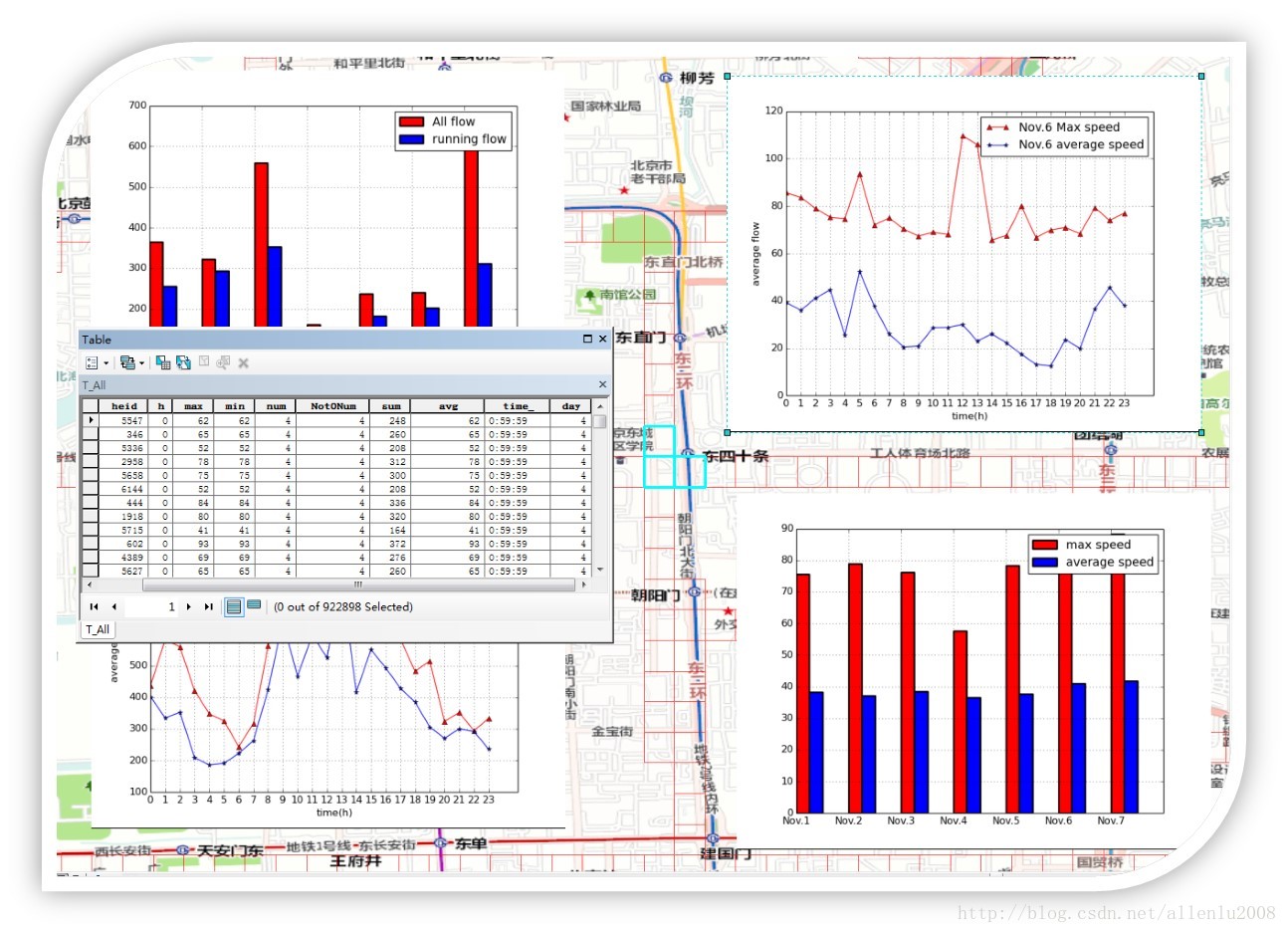
这样的数据分析,实际上与传统数据查询最大的不同点就在于任何一条独立的数据将没有任何的价值(或者价值非常小,也就是常说的:价值密度的问题)。
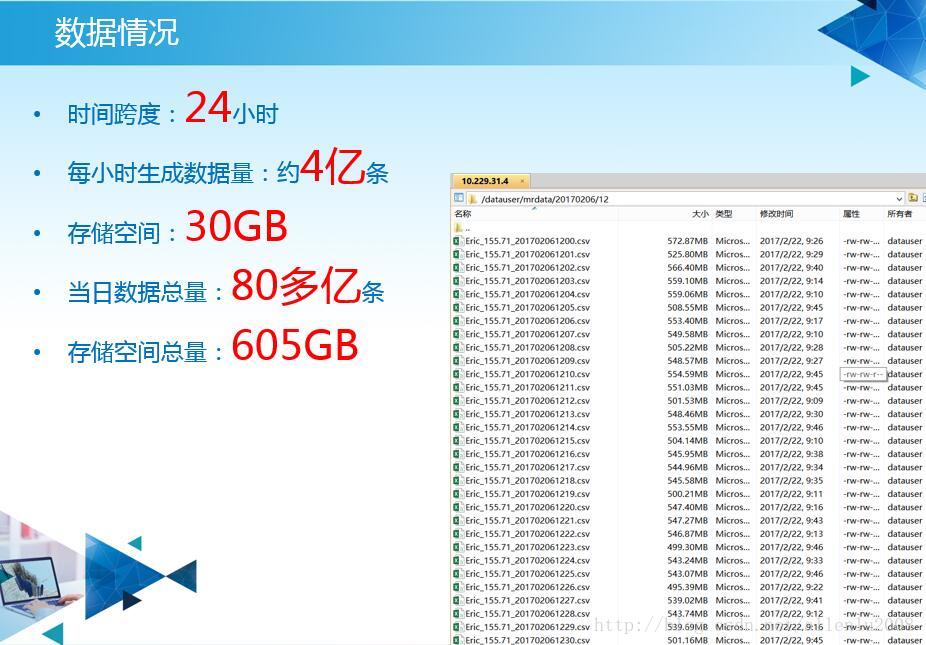
2、生成、获取的时间极快:快到都来不及放进数据库。
比如一个省,一天的信令数据:
3、数据中夹杂大量的噪音(或者错误)数据,传统分析中,遇见错误数据会导致分析过程执行不下去,甚至于分析结果崩溃。
而在大数据环境下,千万甚至亿级规模的数据中,几十条乃至几百几千条数据出现了错误,完全不影响最后分析的结果(因为单条价值密度的原因)。
而且大数据计算方案有极强的容错能力,不会因为个别数据错误,而导致整个系统的崩溃。
4、分析的结果由精确转向置信度概率,比如精确度达到95%和达到99.9999999%,在对结果的使用上,不存在本质性的差异。
快速获取非精确性的结果:如一分钟之内,获取一定区域内的非精确结果(XX河流旁边10公里内,总共有多少农用地?答案是:431万6213.7754亩和430万多亩,两个数字有多大区别,但是前者如果需要10小时,后者只要一分钟,哪个价值更大。)
5、更讲究数据的价值,而非计算的价值。数据的价值包括
数据获取方式(内部(外部?)通过API或者服务的方式,来获取数据,分析的时候,不再需要把数据下载到本地,而是通过服务来进行)。
数据结果的导向(利用中间数据计算出大致需要的结果,而非通过原始数据计算出来的结果。)
数据的直接意义:只要结论,不要过程,也不关心你是用十分钟算出来的,还是一个小时算出来的:如:本次土地确权的数据表明,仅宁夏一个省,农用地实测面积,比二轮承包的合同数据,要多出XXX万亩土地。)
数据的关联意义:利用现有数据,对其他数据进行验证(201x年,发放的农业补贴,有xx实际领取人的实际承包面积与账户不合,其中以xx省最为严重。)
6、中间数据的价值
原始数据通过各种方法清洗、聚合、抽取、计算,生成中间数据。比如离散的LBS点数据可以生成数据链或者数据块。同意,复杂的地块数据可以聚合生成不同分辨率的网格数据,这样网格数据就可以完成大部分的查询和分析的应用。
要研究中间数据,就必须对原始数据和目标分析的空间尺度进行深入的研究,比如在全国范围内所需要的空间尺度(分辨率)和省、市、县不同级别需要的分辨率数据都是不同的,这就需要具体问题具体分析了。
大数据项目架构思考(一):http://zhihu.esrichina.com.cn/article/3336
大数据项目架构思考(二):http://zhihu.esrichina.com.cn/article/3335
大数据项目架构思考(三):http://zhihu.esrichina.com.cn/article/3341
文章来源:http://blog.csdn.net/allenlu2008/article/details/77854085
世界上第一架(也是唯一?的)不锈钢制造的战斗机:国内军迷亲切的称呼它为“青翼蝠王”……从分量上来看,比西方那些用各种合金材料打造的妖艳货压秤多了,但是就这么个超级“秤砣”,不但飞起来了,还创造了当年在速度上面的N多项世界纪录。
所以,毛熊大哥们告诉我们的语录,我们一直记在心头:
进入21世纪的第二个10年,一种名叫“大数据”的技术,突然开始流行起来了,首先是在互联网,然后慢慢的流窜到了传统领域,于是乎,各种以“大数据”为名的宗教开始大行其道:
人们呐……你们罪孽深重呐(重得跟你们的钱包似的)……快使用大数据,哼哼哈嘿……信大数据者得永生……
所以在实际的工作中,有大量的用传统技术无法解决的痛点,都把希望寄托在了大数据技术上面。
比如:上亿级别的地块图斑,希望能够在很短(最好几秒……当年能到毫秒就更好了)的时间内完成各种复杂查询和统计。
什么?你说数据库为什么不行?这是有很多客观原因的。
现在我觉得数据库不行了,那么你不是大数据来了么?这样吧,上大数据(不管你们用Hadoop还是用Spark,先帮我把这个事情给我解决掉。)
如果说,大数据技术类似于制造了一个压路机,提供给需要修路的单位使用,而突然被玩赛车的公司看中了,想用这个压路机来跑F1方程式——理由是:你这个压路机的马力这么大,跑起来肯定很快……
如果我们千方百计告诉客户,压路机马力这么大,但是他的速度不一定会快——比如,他在赛道上,肯定没有F1赛车快。客户勉为其难就算接受了这个的忠告。
但是,毛熊大哥的话记心头……他们会这样问我们:你们的压路机马力这大,发动机肯定很强悍吧?来来来,把你们压路机的发动机拆下来,安装到F1赛车上,那么我们的F1赛车是不是就可以跑得很快了。
客户错了吗?当然没错,他们的理解,就停留在马力大,就速度快的基础上。至于什么架构、技术背景、适用场景、体量重量等等等,都不在他们的考虑范围内。
遇上这种情况,我特别想在心里面问候一句:what the fuck……
但是作为有素质有理想的五好青年,虾神是不能问候WTF,所以就要想办法让压路机在平时主要干修路工作的时候,还要挖掘潜能,跑出F1赛车的速度来。
要了解大数据分析工具到底能做什么?首先要了解大数据分析的一些基本概念。
大数据技术并不是为了专门解决传统模式痛点而产生的,目前解决传统模式只是大数据技术发展中的一个附带的产物。
就像研制压路机的发动机,不是为了让这个发动机可以给F1赛车提速上一样。
大数据这几年被严重的神话了,变成了宗教崇拜。实施大数据项目,应该是有充分且严格的前提条件的,我们近些年遇见的,基本上是以大数据为名,做传统的数据中心和数据分析。因为遇见的数据,除了量以外,都不是大数据意义上的内容。
而大数据意义上的数据,就以LBS数据(比如车辆的GPS)而论,除去大家都有数据量巨大这点以外,有这样一些特点:
1、单条价值密度极低(单条价值密度无限接近与0),任何一个点的GPS数据,都没有任何独立的意义,需要有大量的数据聚集在一起,形成数据链,或者数据块,才会有意义。
比如下面的情况:任何一个点,单独提出来,有啥意义么?
但是,形成数据块或者数据链之后,进行整体的趋势了解:
或者是大量数据的统计性质的信息:
这样的数据分析,实际上与传统数据查询最大的不同点就在于任何一条独立的数据将没有任何的价值(或者价值非常小,也就是常说的:价值密度的问题)。
2、生成、获取的时间极快:快到都来不及放进数据库。
比如一个省,一天的信令数据:
3、数据中夹杂大量的噪音(或者错误)数据,传统分析中,遇见错误数据会导致分析过程执行不下去,甚至于分析结果崩溃。
而在大数据环境下,千万甚至亿级规模的数据中,几十条乃至几百几千条数据出现了错误,完全不影响最后分析的结果(因为单条价值密度的原因)。
而且大数据计算方案有极强的容错能力,不会因为个别数据错误,而导致整个系统的崩溃。
4、分析的结果由精确转向置信度概率,比如精确度达到95%和达到99.9999999%,在对结果的使用上,不存在本质性的差异。
快速获取非精确性的结果:如一分钟之内,获取一定区域内的非精确结果(XX河流旁边10公里内,总共有多少农用地?答案是:431万6213.7754亩和430万多亩,两个数字有多大区别,但是前者如果需要10小时,后者只要一分钟,哪个价值更大。)
5、更讲究数据的价值,而非计算的价值。数据的价值包括
数据获取方式(内部(外部?)通过API或者服务的方式,来获取数据,分析的时候,不再需要把数据下载到本地,而是通过服务来进行)。
数据结果的导向(利用中间数据计算出大致需要的结果,而非通过原始数据计算出来的结果。)
数据的直接意义:只要结论,不要过程,也不关心你是用十分钟算出来的,还是一个小时算出来的:如:本次土地确权的数据表明,仅宁夏一个省,农用地实测面积,比二轮承包的合同数据,要多出XXX万亩土地。)
数据的关联意义:利用现有数据,对其他数据进行验证(201x年,发放的农业补贴,有xx实际领取人的实际承包面积与账户不合,其中以xx省最为严重。)
6、中间数据的价值
原始数据通过各种方法清洗、聚合、抽取、计算,生成中间数据。比如离散的LBS点数据可以生成数据链或者数据块。同意,复杂的地块数据可以聚合生成不同分辨率的网格数据,这样网格数据就可以完成大部分的查询和分析的应用。
要研究中间数据,就必须对原始数据和目标分析的空间尺度进行深入的研究,比如在全国范围内所需要的空间尺度(分辨率)和省、市、县不同级别需要的分辨率数据都是不同的,这就需要具体问题具体分析了。
大数据项目架构思考(一):http://zhihu.esrichina.com.cn/article/3336
大数据项目架构思考(二):http://zhihu.esrichina.com.cn/article/3335
大数据项目架构思考(三):http://zhihu.esrichina.com.cn/article/3341
文章来源:http://blog.csdn.net/allenlu2008/article/details/77854085

