
解密ArcGIS实时大数据的高效存储
分享
大家好,打个招呼先
大家好,在之前给大家介绍过ArcGIS 10.5支持实时大数据的完整方案,超出预料的受到了诸多用户的关注,看来实时大数据会是接下来几年的又一个技术热点了。错过该方案的朋友们,可以看今天的专题里面的第2篇《ArcGIS 10.5,打造实时大数据的平台》,在本文,我想更加深入技术细节,给大家详细介绍下ArcGIS实时大数据采用的技术支撑。
在上面列出的文章《ArcGIS 10.5,打造实时大数据的平台》中讲到,ArcGIS 10.5是一个能够支持实时大数据的平台,通过将原来的GeoEvent扩展模块升级为GeoEvent Server,实时GIS的支撑框架也大为增强,不仅能更好的支持实时数据源的接入、处理和输出,在支持的数据量上更是大幅提升,直接实现对实时大数据的高效接入、分析处理、可视化和实时历史大数据的挖掘分析。
在上面列出的文章《ArcGIS 10.5,打造实时大数据的平台》中讲到,ArcGIS 10.5是一个能够支持实时大数据的平台,通过将原来的GeoEvent扩展模块升级为GeoEvent Server,实时GIS的支撑框架也大为增强,不仅能更好的支持实时数据源的接入、处理和输出,在支持的数据量上更是大幅提升,直接实现对实时大数据的高效接入、分析处理、可视化和实时历史大数据的挖掘分析。

本文重点给大家介绍下ArcGIS实时大数据的高效存储机制。
ArcGIS实时数据存储技术发展回顾
熟悉ArcGIS产品的用户可能知道,ArcGIS 10.2时,实时数据通过GeoEvent扩展模块能够接入ArcGIS平台,在接入的同时即对数据进行分析和处理,同时以各种需要的形式输出,并不对数据进行存储。
ArcGIS 10.3时引入stream service,可视化效率极大提升,能快速显示实时流数据,但仍不能存储实时历史数据,向关系型数据库中写入的速率也极低(200e/s,e/s即每秒处理多少个实时事件)。
ArcGIS 10.4开始引入“时空大数据存储”来处理实时观测数据,时空大数据存储支持分布式部署,每秒可写入的速度根据节点数不断提升(成千上万e/s),新增动态聚合等多种可视化方式,历史数据可以被存储,可视化效率进一步提高(4000e/s)。
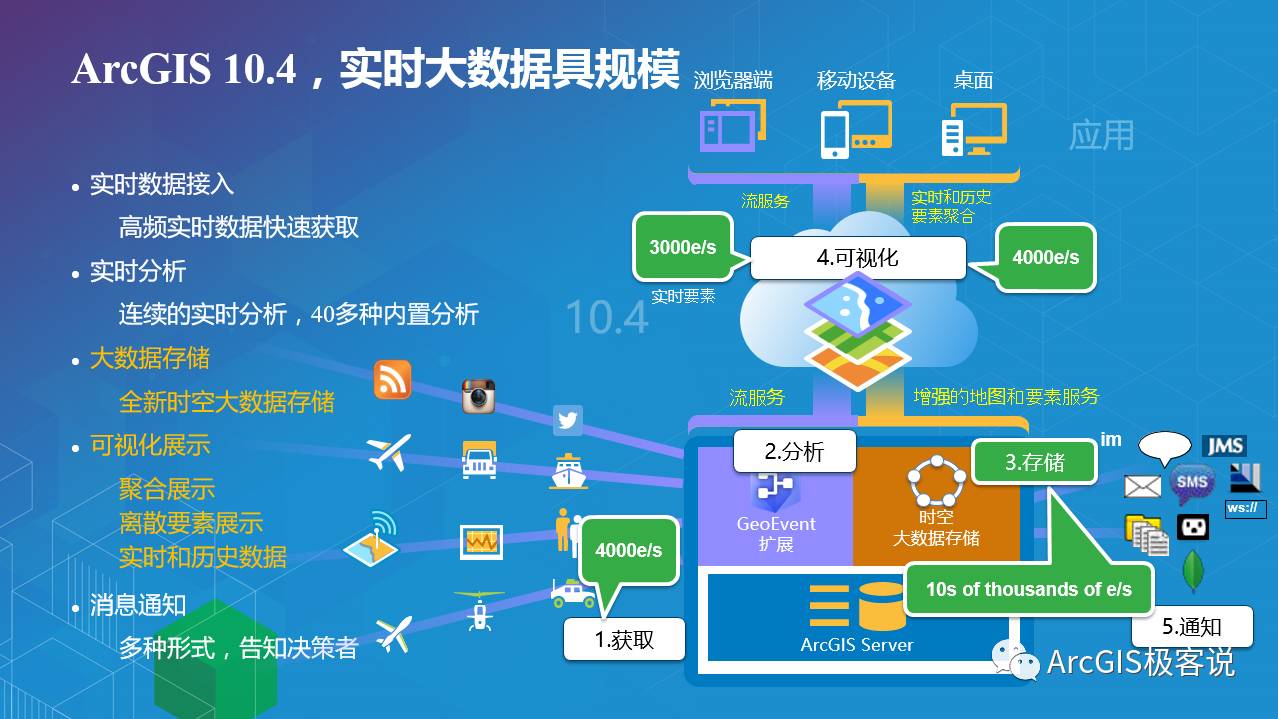
那么,究竟什么是时空大数据存储呢?
时空大数据存储是ArcGIS Data Store具备的一种能力,通过开启该能力并在GeoEvent Server中创建与之对应的输出连接器来实现实时数据的存储。由于时空大数据存储支持分布式部署,并且采用了高效的检索机制,使得GeoEvent接收的实时数据流写入数据库的效率极大提升:
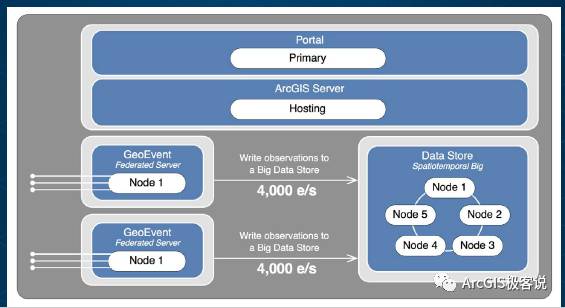
基于Elasticsearch的分布式存储机制
ArcGIS Data Store是ArcGIS Enterprise中默认包含的一个组件,使得用户能够轻松使用ArcGIS来搭建Web GIS平台。最初推出时主要用于为Portal for ArcGIS中发布托管的要素服务和三维服务提供支持。
对于不是数据库专家型用户而言,ArcGIS Data Store是一个简单快捷的数据库配置工具,它里面包含有3种类型的数据库,其中“时空”型即用于存储实时数据。(关于ArcGIS Data Store的更详细内容请看今天专题的第3篇文章《ArcGIS Data Store:航母“基础数据支撑号”的核动力》)。
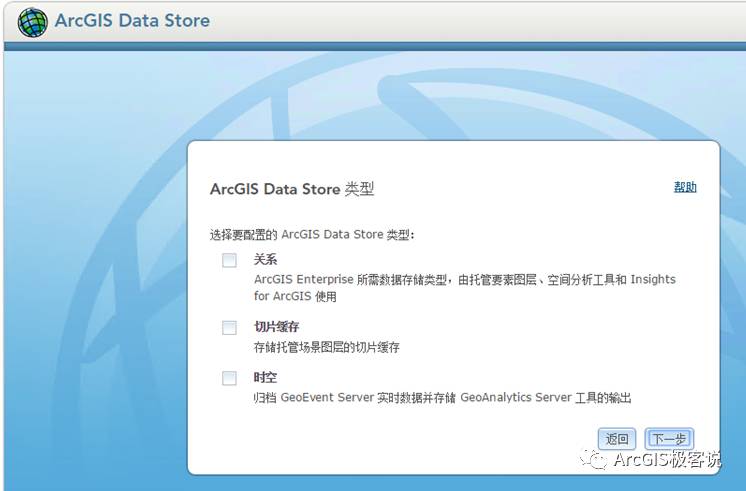
ArcGIS Data Store的“时空”型数据库,其底层技术实际上是用了Elasticsearch,一个基于Apache Lucene(TM)的开源搜索引擎来实现的,使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能。如果看一下ArcGIS Data Store在磁盘上的目录文件我们就可以更清楚的知道这一点,如下图:
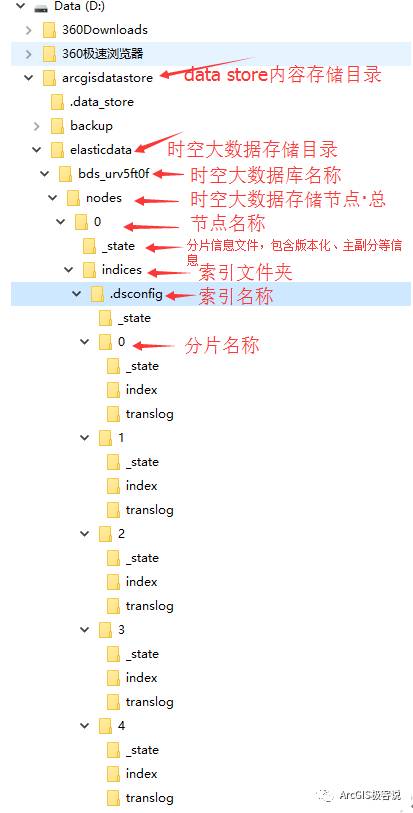
其中,顶层文件夹arcgisdatastore是在创建“时空”型数据库时产生的,elasticdata目录用来存放实时大数据,如果一层层展开分析,熟悉Elasticsearch的用户肯定一眼就能看出,这几乎是跟Elasticsearch的数据存储结构一模一样!
如果还想进一步看看文件夹里面数据的存储情况,如下:
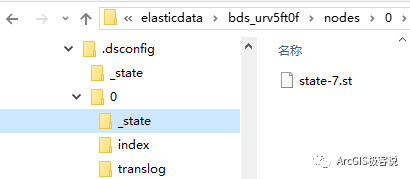

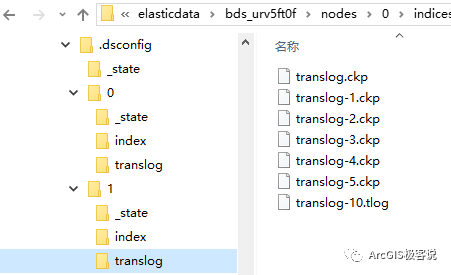
因此,我们可以观察到,在实时数据写入时空大数据存储过程中,这整个时空大数据存储的文件夹都会不断的变化,数据即被以Lucene特有的方式被存储和检索。
另外再啰嗦一句,Elasticsearch的优势不仅仅在于这个高效的索引机制,还有其分布式框架,天然就是为大数据、分布式而生,因此其分布式和高可用部署能力也是毋庸置疑,这也是ArcGIS实时大数据高效读写的有力保证。
ArcGIS实时大数据存储效率初探
基于这种新型的时空大数据存储机制,可想而知具备极高的读写和查询的性能。这就是ArcGIS能支持实时大数据高效存储的根本原因。下图是美国给出的“时空大数据存储”效率,随着ArcGIS Data Store分布式节点增多,存储性能也逐节提高,与传统的关系型数据库相比真的不是一两倍:

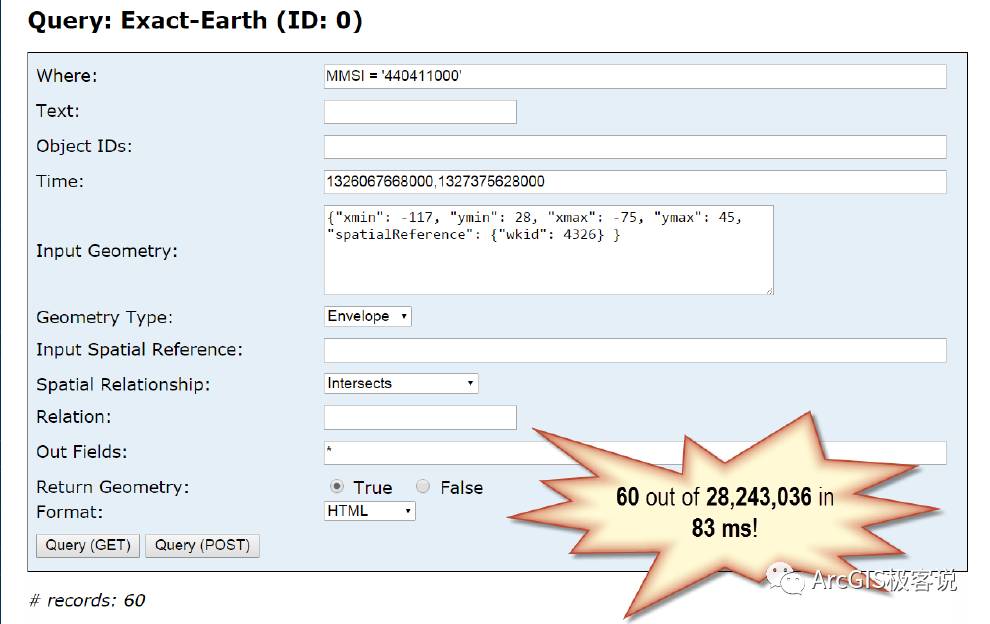
另外美国也给出了基于新型“时空大数据存储”的查询和检索效率,如下图,从28243036(咳咳。。。别数了,我好人做到底,是2千8百多万条)记录中,采用属性、空间和时间多字段联合查询,最终得到60条查询结果居然只用了83毫秒!(居然连半秒钟都不到,这简直不是传统的关系型数据库的查询效率所能比的吧?)
总结下呗
好了,关于ArcGIS实时大数据的存储技术就介绍到这里,相信已经能让大部分GIS技术宅们过足眼瘾,接下来,还会有相关的实时大数据可视化、实时历史大数据挖掘的技术揭秘,请大家保持期待!
文章来源:https://mp.weixin.qq.com/s/wLXcSTtDTEDkcQ1FwVHpLw
-
2017-07-26
大家好,打个招呼先
大家好,在之前给大家介绍过ArcGIS 10.5支持实时大数据的完整方案,超出预料的受到了诸多用户的关注,看来实时大数据会是接下来几年的又一个技术热点了。错过该方案的朋友们,可以看今天的专题里面的第2篇《ArcGIS 10.5,打造实时大数据的平台》,在本文,我想更加深入技术细节,给大家详细介绍下ArcGIS实时大数据采用的技术支撑。
在上面列出的文章《ArcGIS 10.5,打造实时大数据的平台》中讲到,ArcGIS 10.5是一个能够支持实时大数据的平台,通过将原来的GeoEvent扩展模块升级为GeoEvent Server,实时GIS的支撑框架也大为增强,不仅能更好的支持实时数据源的接入、处理和输出,在支持的数据量上更是大幅提升,直接实现对实时大数据的高效接入、分析处理、可视化和实时历史大数据的挖掘分析。
在上面列出的文章《ArcGIS 10.5,打造实时大数据的平台》中讲到,ArcGIS 10.5是一个能够支持实时大数据的平台,通过将原来的GeoEvent扩展模块升级为GeoEvent Server,实时GIS的支撑框架也大为增强,不仅能更好的支持实时数据源的接入、处理和输出,在支持的数据量上更是大幅提升,直接实现对实时大数据的高效接入、分析处理、可视化和实时历史大数据的挖掘分析。
本文重点给大家介绍下ArcGIS实时大数据的高效存储机制。
ArcGIS实时数据存储技术发展回顾
熟悉ArcGIS产品的用户可能知道,ArcGIS 10.2时,实时数据通过GeoEvent扩展模块能够接入ArcGIS平台,在接入的同时即对数据进行分析和处理,同时以各种需要的形式输出,并不对数据进行存储。
ArcGIS 10.3时引入stream service,可视化效率极大提升,能快速显示实时流数据,但仍不能存储实时历史数据,向关系型数据库中写入的速率也极低(200e/s,e/s即每秒处理多少个实时事件)。
ArcGIS 10.4开始引入“时空大数据存储”来处理实时观测数据,时空大数据存储支持分布式部署,每秒可写入的速度根据节点数不断提升(成千上万e/s),新增动态聚合等多种可视化方式,历史数据可以被存储,可视化效率进一步提高(4000e/s)。
那么,究竟什么是时空大数据存储呢?
时空大数据存储是ArcGIS Data Store具备的一种能力,通过开启该能力并在GeoEvent Server中创建与之对应的输出连接器来实现实时数据的存储。由于时空大数据存储支持分布式部署,并且采用了高效的检索机制,使得GeoEvent接收的实时数据流写入数据库的效率极大提升:
基于Elasticsearch的分布式存储机制
ArcGIS Data Store是ArcGIS Enterprise中默认包含的一个组件,使得用户能够轻松使用ArcGIS来搭建Web GIS平台。最初推出时主要用于为Portal for ArcGIS中发布托管的要素服务和三维服务提供支持。
对于不是数据库专家型用户而言,ArcGIS Data Store是一个简单快捷的数据库配置工具,它里面包含有3种类型的数据库,其中“时空”型即用于存储实时数据。(关于ArcGIS Data Store的更详细内容请看今天专题的第3篇文章《ArcGIS Data Store:航母“基础数据支撑号”的核动力》)。
ArcGIS Data Store的“时空”型数据库,其底层技术实际上是用了Elasticsearch,一个基于Apache Lucene(TM)的开源搜索引擎来实现的,使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能。如果看一下ArcGIS Data Store在磁盘上的目录文件我们就可以更清楚的知道这一点,如下图:
其中,顶层文件夹arcgisdatastore是在创建“时空”型数据库时产生的,elasticdata目录用来存放实时大数据,如果一层层展开分析,熟悉Elasticsearch的用户肯定一眼就能看出,这几乎是跟Elasticsearch的数据存储结构一模一样!
如果还想进一步看看文件夹里面数据的存储情况,如下:
- _state文件夹下的state-7.st文件:分片信息文件,存储版本号、主副分等信息;
- index文件夹:存储真正的索引信息,在实时数据往里面写的时候,这些索引会不停的更新,文件大小也会不停增大。具体每个文件格式存储的信息本文由于篇幅有限就不展开讲了,相信能看到这里的技术大牛们,这个问题也难不倒大家;
- translog文件夹:Lucene的变化只有在提交到磁盘时才会进行,但这是一个相对耗资源的操作,因此不是每个索引或删除操作都会被提交并记录,当处理进程结束或者HW失败时,发生在提交之前那些操作就会丢失,为了避免这种丢失,每一个分片都会有一个transaction文件来记录这些改变。
因此,我们可以观察到,在实时数据写入时空大数据存储过程中,这整个时空大数据存储的文件夹都会不断的变化,数据即被以Lucene特有的方式被存储和检索。
另外再啰嗦一句,Elasticsearch的优势不仅仅在于这个高效的索引机制,还有其分布式框架,天然就是为大数据、分布式而生,因此其分布式和高可用部署能力也是毋庸置疑,这也是ArcGIS实时大数据高效读写的有力保证。
ArcGIS实时大数据存储效率初探
基于这种新型的时空大数据存储机制,可想而知具备极高的读写和查询的性能。这就是ArcGIS能支持实时大数据高效存储的根本原因。下图是美国给出的“时空大数据存储”效率,随着ArcGIS Data Store分布式节点增多,存储性能也逐节提高,与传统的关系型数据库相比真的不是一两倍:
另外美国也给出了基于新型“时空大数据存储”的查询和检索效率,如下图,从28243036(咳咳。。。别数了,我好人做到底,是2千8百多万条)记录中,采用属性、空间和时间多字段联合查询,最终得到60条查询结果居然只用了83毫秒!(居然连半秒钟都不到,这简直不是传统的关系型数据库的查询效率所能比的吧?)
总结下呗
好了,关于ArcGIS实时大数据的存储技术就介绍到这里,相信已经能让大部分GIS技术宅们过足眼瘾,接下来,还会有相关的实时大数据可视化、实时历史大数据挖掘的技术揭秘,请大家保持期待!
文章来源:https://mp.weixin.qq.com/s/wLXcSTtDTEDkcQ1FwVHpLw
