
白话空间统计之四:P值和Z得分(下)
分享
-
2016-01-12
上篇讲了P值与Z得分的一些基本概念,大家其实也都知道,P值和Z得分其实是有一定的相应关系的,Z得分有正负两种结果,而P值有显著和不显著两种可能。
如果按照我们一般的思维,P值和Z得分就应该有4种组合。不过实际上他们只有三种组合,如下:

可以看见,只要P值不具备统计学上的显著特征,那么Z值不论是正负,都是一个结果。
那么为什么P值如此之重要呢?
上一篇文章说过了,P值是用来检验随机过程的,如果发现你的P值过大,即说明要分析的这份数据有很大的可能是随机结果了。
说的简单一点,当我们拿到一份数据的时候,因为主要是做空间相关性嘛,所以如果仅仅考虑空间的位置,而在空间位置上无非就是离散、聚集和随机三种可能,即z得分就已经可以完全衡量了,为什么还需要有p值呢?
p值的意义在于,我们在分析数据的时候,不可能简简单单的只对空间位置进行分析,还需要考虑到每个要素上面的属性信息(毛博士语录:凡事不考虑属性的空间聚类,都是耍流氓)。
当我们发现,每个要素上面的属性信息,都是随机出现的。也就是说,这些属性值,都随意的出现在了任何一个空间位置上,而且每个空间位置,都有可能出现任何一个的属性值,完全没有规律。就像素数一样,不经意的就出现在数轴上,那么是不是瞬间就觉得抓狂了?
那么,这种出现这种情况,你的数据,在空间上,可能是有明显聚集或者离散的特征,但是在属性上出现了随机概率,这样也是问题的。最起码表示,你选择要计算的这个属性值,不具备参与计算你的空间相关性的分析,基本上就表示你可以pass掉这个属性值,选择其他的数值来计算了。
我们举个例子:(声明:以下数据是人为做出来的数据,没有实际价值,仅仅为了说明P值的含义)
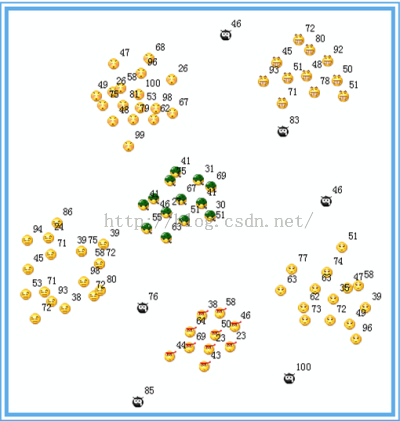
还是第一天用的那个学生做课间操的场景,直接跳到散操之后,如下图:

现在可以很明显的看见,在空间上,一定是具有相关性的,那么作为一个数据分析人员,我们来选择不同的属性,用以寻找他们的相关性。
在计算之前,我们预先设定数据的置信度为95%。如果满足这个置信度,就说明我们的数据是有分析价值的(这个值属于一般保守状态……)
首先,作为学生,最容易肯定就是选择他们的成绩作为分析变量。如下:
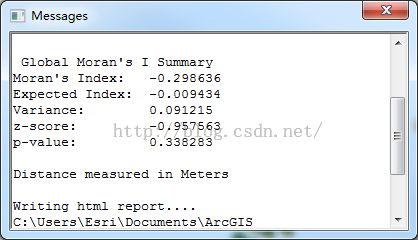
可以看见,P值居然高达0.3,超出我们设定的置信度6倍!完全就可以确定,这个数据几乎就是由随机过程来生成的,事实上也是如此,我直接用随机函数生成了成绩的值,如下:
然后我们来换一个数据进行计算,改为性别,计算的结果如下:
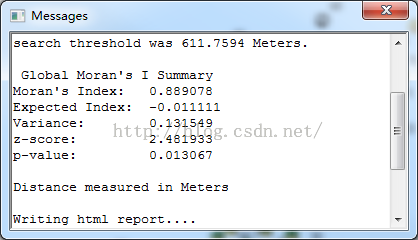
P值为0.013,置信度大于95%,小于99%,已经超过我们设定的阈值,所以有分析的价值,而且z值得分为2.48,表明了明显的聚集特性。
实际上,也是,查看数据如下:

所以得出结论,上一份数据,如果用成绩来作为分析属性,那么基本上就不靠谱,所以我们在研究这些学生相关性的时候,就可以排除学习成绩这个因素了。
当然,这份数据是我人工做出来的,只是为了说明p值的问题,没有任何的实际价值,也绝对不是实际情况,切切不可误会。
下面给出A、B、C三种情况的官方解释:

最后加两句,P值本身有很大的争议,不可滥用,一定要慎之又慎,关于P值问题的,此文章后面的那篇文章《慎用P值》,可以在博客里面查看,也可以关注虾神的公众号:

文章来源:http://blog.csdn.net/allenlu2008/article/details/47259609
如果按照我们一般的思维,P值和Z得分就应该有4种组合。不过实际上他们只有三种组合,如下:
可以看见,只要P值不具备统计学上的显著特征,那么Z值不论是正负,都是一个结果。
那么为什么P值如此之重要呢?
上一篇文章说过了,P值是用来检验随机过程的,如果发现你的P值过大,即说明要分析的这份数据有很大的可能是随机结果了。
说的简单一点,当我们拿到一份数据的时候,因为主要是做空间相关性嘛,所以如果仅仅考虑空间的位置,而在空间位置上无非就是离散、聚集和随机三种可能,即z得分就已经可以完全衡量了,为什么还需要有p值呢?
p值的意义在于,我们在分析数据的时候,不可能简简单单的只对空间位置进行分析,还需要考虑到每个要素上面的属性信息(毛博士语录:凡事不考虑属性的空间聚类,都是耍流氓)。
当我们发现,每个要素上面的属性信息,都是随机出现的。也就是说,这些属性值,都随意的出现在了任何一个空间位置上,而且每个空间位置,都有可能出现任何一个的属性值,完全没有规律。就像素数一样,不经意的就出现在数轴上,那么是不是瞬间就觉得抓狂了?
那么,这种出现这种情况,你的数据,在空间上,可能是有明显聚集或者离散的特征,但是在属性上出现了随机概率,这样也是问题的。最起码表示,你选择要计算的这个属性值,不具备参与计算你的空间相关性的分析,基本上就表示你可以pass掉这个属性值,选择其他的数值来计算了。
我们举个例子:(声明:以下数据是人为做出来的数据,没有实际价值,仅仅为了说明P值的含义)
还是第一天用的那个学生做课间操的场景,直接跳到散操之后,如下图:
现在可以很明显的看见,在空间上,一定是具有相关性的,那么作为一个数据分析人员,我们来选择不同的属性,用以寻找他们的相关性。
在计算之前,我们预先设定数据的置信度为95%。如果满足这个置信度,就说明我们的数据是有分析价值的(这个值属于一般保守状态……)
首先,作为学生,最容易肯定就是选择他们的成绩作为分析变量。如下:
可以看见,P值居然高达0.3,超出我们设定的置信度6倍!完全就可以确定,这个数据几乎就是由随机过程来生成的,事实上也是如此,我直接用随机函数生成了成绩的值,如下:
然后我们来换一个数据进行计算,改为性别,计算的结果如下:
P值为0.013,置信度大于95%,小于99%,已经超过我们设定的阈值,所以有分析的价值,而且z值得分为2.48,表明了明显的聚集特性。
实际上,也是,查看数据如下:
所以得出结论,上一份数据,如果用成绩来作为分析属性,那么基本上就不靠谱,所以我们在研究这些学生相关性的时候,就可以排除学习成绩这个因素了。
当然,这份数据是我人工做出来的,只是为了说明p值的问题,没有任何的实际价值,也绝对不是实际情况,切切不可误会。
下面给出A、B、C三种情况的官方解释:
最后加两句,P值本身有很大的争议,不可滥用,一定要慎之又慎,关于P值问题的,此文章后面的那篇文章《慎用P值》,可以在博客里面查看,也可以关注虾神的公众号:
文章来源:http://blog.csdn.net/allenlu2008/article/details/47259609
